标签 学习 下的文章
线性代数的本质
- 作者: TheBadZhang
- 时间:
- 分类: 编程,学习
- 评论
https://blog.csdn.net/a514371309/article/details/81604194
原文链接:https://www.cnblogs.com/TenosDoIt/p/3214096.html
从大学开始接触矩阵论和线性代数,记了很多公式,但是总感觉徘徊在线性代数的门外没有进去,感觉并没有接触到它的核心概念,不巧看到了这篇博客,顿时醍醐灌顶,豁然开朗,记录与此:
比如说,在全国一般工科院系教学中应用最广泛的同济线性代数教材(现在到了第四版),一上来就介绍逆序数这个古怪概念,然后用逆序数给出行列式的一个极不直观的定义,接着是一些简直犯傻的行列式性质和习题——把这行乘一个系数加到另一行上,再把那一列减过来,折腾得那叫一个热闹,可就是压根看不出这个东西有嘛用。
大多数像我一样资质平庸的学生到这里就有点犯晕:连这是个什么东西都模模糊糊的,就开始钻火圈表演了,这未免太无厘头了吧!于是开始有人逃课,更多的人开始抄作业。这下就中招了,因为其后的发展可以用一句峰回路转来形容,紧跟着这个无厘头的行列式的,是一个同样无厘头但是伟大的无以复加的家伙的出场——矩阵来了!多年之后,我才明白,当老师犯傻似地用中括号把一堆傻了吧叽的数括起来,并且不紧不慢地说:“这个东西叫做矩阵”的时候,我的数学生涯掀开了何等悲壮辛酸、惨绝人寰的一幕!自那以后,在几乎所有跟“学问”二字稍微沾点边的东西里,矩阵这个家伙从不缺席。对于我这个没能一次搞定线性代数的笨蛋来说,矩阵老大的不请自来每每搞得我灰头土脸,头破血流。长期以来,我在阅读中一见矩阵,就如同阿Q见到了假洋鬼子,揉揉额角就绕道走。
事实上,我并不是特例。一般工科学生初学线性代数,通常都会感到困难。这种情形在国内外皆然。瑞典数学家Lars Garding在其名著Encounter withMathematics中说:“如果不熟悉线性代数的概念,要去学习自然科学,现在看来就和文盲差不多。然而“按照现行的国际标准,线性代数是通过公理化来表述的,它是第二代数学模型,这就带来了教学上的困难。”事实上,当我们开始学习线性代数的时候,不知不觉就进入了“第二代数学模型”的范畴当中,这意味着数学的表述方式和抽象性有了一次全面的进化,对于从小一直在“第一代数学模型”,即以实用为导向的、具体的数学模型中学习的我们来说,在没有并明确告知的情况下进行如此剧烈的paradigm shift,不感到困难才是奇怪的。
大部分工科学生,往往是在学习了一些后继课程,如数值分析、数学规划、矩阵论之后,才逐渐能够理解和熟练运用线性代数。即便如此,不少人即使能够很熟练地以线性代数为工具进行科研和应用工作,但对于很多这门课程的初学者提出的、看上去是很基础的问题却并不清楚。比如说:
1、矩阵究竟是什么东西?
2、向量可以被认为是具有n个相互独立的性质(维度)的对象的表示,矩阵又是什么呢?
3、我们如果认为矩阵是一组列(行)向量组成的新的复合向量的展开式,那么为什么这种展开式具有如此广泛的应用?特别是,为什么偏偏二维的展开式如此有用?
4、如果矩阵中每一个元素又是一个向量,那么我们再展开一次,变成三维的立方阵,是不是更有用?
5、矩阵的乘法规则究竟为什么这样规定?为什么这样一种怪异的乘法规则却能够在实践中发挥如此巨大的功效?很多看上去似乎是完全不相关的问题,最后竟然都归结到矩阵的乘法,这难道不是很奇妙的事情?难道在矩阵乘法那看上去莫名其妙的规则下面,包含着世界的某些本质规律?如果是的话,这些本质规律是什么?
6、行列式究竟是一个什么东西?为什么会有如此怪异的计算规则?行列式与其对应方阵本质上是什么关系?为什么只有方阵才有对应的行列式,而一般矩阵就没有(不要觉得这个问题很蠢,如果必要,针对mxn矩阵定义行列式不是做不到的,之所以不做,是因为没有这个必要,但是为什么没有这个必要)?而且,行列式的计算规则,看上去跟矩阵的任何计算规则都没有直观的联系,为什么又在很多方面决定了矩阵的性质?难道这一切仅是巧合?
7、矩阵为什么可以分块计算?分块计算这件事情看上去是那么随意,为什么竟是可行的?
8、对于矩阵转置运算AT,有(AB)T=BTAT,对于矩阵求逆运算A-1,有(AB)-1=B-1A-1。两个看上去完全没有什么关系的运算,为什么有着类似的性质?这仅仅是巧合吗?
9、为什么说P−1AP得到的矩阵与A矩阵“相似”?这里的“相似”是什么意思?
10、特征值和特征向量的本质是什么?它们定义就让人很惊讶,因为Ax=λx,一个诺大的矩阵的效应,竟然不过相当于一个小小的数λ,确实有点奇妙。但何至于用“特征”甚至“本征”来界定?它们刻划的究竟是什么?
这样的一类问题,经常让使用线性代数已经很多年的人都感到为难。就好像大人面对小孩子的刨根问底,最后总会迫不得已地说“就这样吧,到此为止”一样,
面对这样的问题,很多老手们最后也只能用:“就是这么规定的,你接受并且记住就好”来搪塞。
然而,这样的问题如果不能获得回答,线性代数对于我们来说就是一个粗暴的、不讲道理的、莫名其妙的规则集合,我们会感到,自己并不是在学习一门学问,而是被不由分说地“抛到”一个强制的世界中,只是在考试的皮鞭挥舞之下被迫赶路,全然无法领略其中的美妙、和谐与统一。直到多年以后,我们已经发觉这门学问如此的有用,却仍然会非常迷惑:怎么这么凑巧?我认为这是我们的线性代数教学中直觉性丧失的后果。上述这些涉及到“如何能”、“怎么会”的问题,仅仅通过纯粹的数学证明来回答,是不能令提问者满意的。比如,如果你通过一般的证明方法论证了矩阵分块运算确实可行,那么这并不能够让提问者的疑惑得到解决。他们真正的困惑是:矩阵分块运算为什么竟然是可行的?究竟只是凑巧,还是说这是由矩阵这种对象的某种本质所必然决定的?如果是后者,那么矩阵的这些本质是什么?只要对上述那些问题稍加考虑,我们就会发现,所有这些问题都不是单纯依靠数学证明所能够解决的。像我们的教科书那样,凡事用数学证明,最后培养出来的学生,只能熟练地使用工具,却欠缺真正意义上的理解。
自从1930年代法国布尔巴基学派兴起以来,数学的公理化、系统性描述已经获得巨大的成功,这使得我们接受的数学教育在严谨性上大大提高。然而数学公理化的一个备受争议的副作用,就是一般数学教育中直觉性的丧失。数学家们似乎认为直觉性与抽象性是矛盾的,因此毫不犹豫地牺牲掉前者。然而包括我本人在内的很多人都对此表示怀疑,我们不认为直觉性与抽象性一定相互矛盾,特别是在数学教育中和数学教材中,帮助学生建立直觉,有助于它们理解那些抽象的概念,进而理解数学的本质。反之,如果一味注重形式上的严格性,学生就好像被迫进行钻火圈表演的小白鼠一样,变成枯燥的规则的奴隶。
对于线性代数的类似上述所提到的一些直觉性的问题,两年多来我断断续续地反复思考了四、五次,为此阅读了好几本国内外线性代数、数值分析、代数和数学通论性书籍,其中像前苏联的名著《数学:它的内容、方法和意义》、龚昇教授的《线性代数五讲》、前面提到的Encounter with Mathematics(《数学概观》)以及Thomas A. Garrity的《数学拾遗》都给我很大的启发。不过即使如此,我对这个主题的认识也经历了好几次自我否定。比如以前思考的一些结论曾经写在自己的blog里,但是现在看来,这些结论基本上都是错误的。因此打算把自己现在的有关理解比较完整地记录下来,一方面是因为我觉得现在的理解比较成熟了,可以拿出来与别人探讨,向别人请教。另一方面,如果以后再有进一步的认识,把现在的理解给推翻了,那现在写的这个snapshot也是很有意义的。
线性空间
今天先谈谈对线形空间和矩阵的几个核心概念的理解。这些东西大部分是凭着自己的理解写出来的,基本上不抄书,可能有错误的地方,希望能够被指出。但我希望做到直觉,也就是说能把数学背后说的实质问题说出来。
首先说说空间(space),这个概念是现代数学的命根子之一,从拓扑空间开始,一步步往上加定义,可以形成很多空间。线形空间其实还是比较初级的,如果在里面定义了范数,就成了赋范线性空间。赋范线性空间满足完备性,就成了巴那赫空间;赋范线性空间中定义角度,就有了内积空间,内积空间再满足完备性,就得到希尔伯特空间。总之,空间有很多种。你要是去看某种空间的数学定义,大致都是:存在一个集合,在这个集合上定义某某概念,然后满足某些性质,就可以被称为空间。这未免有点奇怪,为什么要用“空间”来称呼一些这样的集合呢?大家将会看到,其实这是很有道理的。我们一般人最熟悉的空间,毫无疑问就是我们生活在其中的(按照牛顿的绝对时空观)的三维空间,从数学上说,这是一个三维的欧几里德空间,我们先不管那么多,先看看我们熟悉的这样一个空间有些什么最基本的特点。仔细想想我们就会知道,这个三维的空间:
1.由很多(实际上是无穷多个)位置点组成;
2.这些点之间存在相对的关系;
3.可以在空间中定义长度、角度;
4.这个空间可以容纳运动,这里我们所说的运动是从一个点到另一个点的移动(变换),而不是微积分意义上的“连续”性的运动。
上面的这些性质中,最最关键的是第4条。第1、2条只能说是空间的基础,不算是空间特有的性质,凡是讨论数学问题,都得有一个集合,大多数还得在这个集合上定义一些结构(关系),并不是说有了这些就算是空间。而第3条太特殊,其他的空间不需要具备,更不是关键的性质。只有第4条是空间的本质,也就是说,容纳运动是空间的本质特征。认识到了这些,我们就可以把我们关于三维空间的认识扩展到其他的空间。事实上,不管是什么空间,都必须容纳和支持在其中发生的符合规则的运动(变换)。你会发现,在某种空间中往往会存在一种相对应的变换,比如拓扑空间中有拓扑变换,线性空间中有线性变换,仿射空间中有仿射变换,其实这些变换都只不过是对应空间中允许的运动形式而已。 因此只要知道,“空间”是容纳运动的一个对象集合,而变换则规定了对应空间的运动。 下面我们来看看线性空间。线性空间的定义任何一本书上都有,但是既然我们承认线性空间是个空间,那么有两个最基本的问题必须首先得到解决,那就是:
1.空间是一个对象集合,线性空间也是空间,所以也是一个对象集合。那么线性空间是什么样的对象的集合?或者说,线性空间中的对象有什么共同点吗?
2.线性空间中的运动如何表述的?也就是,线性变换是如何表示的?
我们先来回答第一个问题,回答这个问题的时候其实是不用拐弯抹角的,可以直截了当的给出答案:线性空间中的任何一个对象,通过选取基和坐标的办法,都可以表达为向量的形式。通常的向量空间我就不说了,举两个不那么平凡的例子:
1、L1是最高次项不大于n次的多项式的全体构成一个线性空间,也就是说,这个线性空间中的每一个对象是一个多项式。如果我们以x0,x1,...,xn为基,那么任何一个这样的多项式都可以表达为一组n+1维向量,其中的每一个分量ai其实就是多项式中xi−1项的系数。值得说明的是,基的选取有多种办法,只要所选取的那一组基线性无关就可以。这要用到后面提到的概念了,所以这里先不说,提一下而已。
2、L2是闭区间[a, b]上的n阶连续可微函数的全体,构成一个线性空间。也就是说,这个线性空间的每一个对象是一个连续函数。对于其中任何一个连续函数,根据魏尔斯特拉斯定理,一定可以找到最高次项不大于n的多项式函数,使之与该连续函数的差为0,也就是说,完全相等。这样就把问题归结为L1了。后面就不用再重复了。
所以说, 向量是很厉害的,只要你找到合适的基,用向量可以表示线性空间里任何一个对象。这里头大有文章,因为向量表面上只是一列数,但是其实由于它的有序性,所以除了这些数本身携带的信息之外,还可以在每个数的对应位置上携带信息。为什么在程序设计中数组最简单,却又威力无穷呢?根本原因就在于此。
这是另一个问题了,这里就不说了。
下面来回答第二个问题,这个问题的回答会涉及到线性代数的一个最根本的问题。线性空间中的运动,被称为线性变换。也就是说,你从线性空间中的一个点运动到任意的另外一个点,都可以通过一个线性变化来完成。那么,线性变换如何表示呢?很有意思,在线性空间中,当你选定一组基之后,不仅可以用一个向量来描述空间中的任何一个对象,而且可以用矩阵来描述该空间中的任何一个运动(变换)。而使某个对象发生对应运动的方法,就是用代表那个运动的矩阵,乘以代表那个对象的向量。简而言之,在线性空间中选定基之后,向量刻画对象,矩阵刻画对象的运动,用矩阵与向量的乘法施加运动。是的,矩阵的本质是运动的描述。如果以后有人问你矩阵是什么,那么你就可以响亮地告诉他,矩阵的本质是运动的描述。
可是多么有意思啊,向量本身不是也可以看成是n x 1矩阵吗?这实在是很奇妙,一个空间中的对象和运动竟然可以用相类同的方式表示。能说这是巧合吗?如果是巧合的话,那可真是幸运的巧合!可以说,线性代数中大多数奇妙的性质,均与这个巧合有直接的关系。
接着理解矩阵,上面说“矩阵是运动的描述”,到现在为止,好像大家都还没什么意见。但是我相信早晚会有数学系出身的网友来拍板转。因为运动这个概念,在数学和物理里是跟微积分联系在一起的。我们学习微积分的时候,总会有人照本宣科地告诉你,初等数学是研究常量的数学,是研究静态的数学,高等数学是变量的数学,是研究运动的数学。大家口口相传,差不多人人都知道这句话。但是真知道这句话说的是什么意思的人,好像也不多。
因为这篇文章不是讲微积分的,所以我就不多说了。有兴趣的读者可以去看看齐民友教授写的《重温微积分》。我就是读了这本书开头的部分,才明白“高等数学是研究运动的数学”这句话的道理。不过在我这个《理解矩阵》的文章里,“运动”的概念不是微积分中的连续性的运动,而是瞬间发生的变化。比如这个时刻在A点,经过一个“运动”,一下子就“跃迁”到了B点,其中不需要经过A点与B点之间的任何一个点。这样的“运动”,或者说“跃迁”,是违反我们日常的经验的。不过了解一点量子物理常识的人,就会立刻指出,量子(例如电子)在不同的能量级轨道上跳跃,就是瞬间发生的,具有这样一种跃迁行为。所以说,自然界中并不是没有这种运动现象,只不过宏观上我们观察不到。但是不管怎么说,“运动”这个词用在这里,还是容易产生歧义的,说得更确切些,应该是“跃迁”。因此这句话可以改成:
“矩阵是线性空间里跃迁的描述”。可是这样说又太物理,也就是说太具体,而不够数学,也就是说不够抽象。因此我们最后换用一个正牌的数学术语——变换,来描述这个事情。这样一说,大家就应该明白了,所谓变换,其实就是空间里从一个点(元素/对象)到另一个点(元素/对象)的跃迁。比如说,仿射变换,就是在仿射空间里从一个点到另一个点的跃迁。
附带说一下,这个仿射空间跟向量空间是亲兄弟。做计算机图形学的朋友都知道,尽管描述一个三维对象只需要三维向量,但所有的计算机图形学变换矩阵都是4x4的。说其原因,很多书上都写着“为了使用中方便”,这在我看来简直就是企图蒙混过关。真正的原因,是因为在计算机图形学里应用的图形变换,实际上是在仿射空间而不是向量空间中进行的。想想看,在向量空间里相一个向量平行移动以后仍是相同的那个向量,而现实世界等长的两个平行线段当然不能被认为同一个东西,所以计算机图形学的生存空间实际上是仿射空间。而仿射变换的矩阵表示根本就是4x4的。有兴趣的读者可以去看《计算机图形学——几何工具算法详解》。
一旦我们理解了“变换”这个概念,矩阵的定义就变成:矩阵是线性空间里的变换的描述。到这里为止,我们终于得到了一个看上去比较数学的定义。不过还要多说几句。教材上一般是这么说的,在一个线性空间V里的一个线性变换T,当选定一组基之后,就可以表示为矩阵。因此我们还要说清楚到底什么是线性变换,什么是基,什么叫选定一组基。线性变换的定义是很简单的,设有一种变换T,使得对于线性空间V中间任何两个不相同的对象x和y,以及任意实数a和b,有:T(ax+by)=aT(x)+bT(y),那么就称T为线性变换。定义都是这么写的,但是光看定义还得不到直觉的理解。线性变换究竟是一种什么样的变换?我们刚才说了,变换是从空间的一个点跃迁到另一个点,而线性变换,就是从一个线性空间V的某一个点跃迁到另一个线性空间W的另一个点的运动。这句话里蕴含着一层意思,就是说一个点不仅可以变换到同一个线性空间中的另一个点,而且可以变换到另一个线性空间中的另一个点去。不管你怎么变,只要变换前后都是线性空间中的对象,这个变换就一定是线性变换,也就一定可以用一个非奇异矩阵来描述。而你用一个非奇异矩阵去描述的一个变换,一定是一个线性变换。
有的人可能要问,这里为什么要强调非奇异矩阵?所谓非奇异,只对方阵有意义,那么非方阵的情况怎么样?这个说起来就会比较冗长了,最后要把线性变换作为一种映射,并且讨论其映射性质,以及线性变换的核与像等概念才能彻底讲清楚。
以下我们只探讨最常用、最有用的一种变换,就是在同一个线性空间之内的线性变换。也就是说,下面所说的矩阵,不作说明的话,就是方阵,而且是非奇异方阵。学习一门学问,最重要的是把握主干内容,迅速建立对于这门学问的整体概念,不必一开始就考虑所有的细枝末节和特殊情况,自乱阵脚。
什么是基呢?这个问题在后面还要大讲一番,这里只要把基看成是线性空间里的坐标系就可以了。注意是坐标系,不是坐标值,这两者可是一个“对立矛盾统一体”。这样一来,“选定一组基”就是说在线性空间里选定一个坐标系。好,最后我们把矩阵的定义完善如下:“矩阵是线性空间中的线性变换的一个描述。在一个线性空间中,只要我们选定一组基,那么对于任何一个线性变换,都能够用一个确定的矩阵来加以描述。”理解这句话的关键,在于把“线性变换”与“线性变换的一个描述”区别开。一个是那个对象,一个是对那个对象的表述。就好像我们熟悉的面向对象编程中,一个对象可以有多个引用,每个引用可以叫不同的名字,但都是指的同一个对象。如果还不形象,那就干脆来个很俗的类比。比如有一头猪,你打算给它拍照片,只要你给照相机选定了一个镜头位置,那么就可以给这头猪拍一张照片。这个照片可以看成是这头猪的一个描述,但只是一个片面的的描述,因为换一个镜头位置给这头猪拍照,能得到一张不同的照片,也是这头猪的另一个片面的描述。所有这样照出来的照片都是这同一头猪的描述,但是又都不是这头猪本身。同样的,对于一个线性变换,只要你选定一组基,那么就可以找到一个矩阵来描述这个线性变换。换一组基,就得到一个不同的矩阵。所有这些矩阵都是这同一个线性变换的描述,但又都不是线性变换本身。
但是这样的话,问题就来了如果你给我两张猪的照片,我怎么知道这两张照片上的是同一头猪呢?同样的,你给我两个矩阵,我怎么知道这两个矩阵是描述的同一个线性变换呢?如果是同一个线性变换的不同的矩阵描述,那就是本家兄弟了,见面不认识,岂不成了笑话。好在,我们可以找到同一个线性变换的矩阵兄弟们的一个性质,那就是:若矩阵A与B是同一个线性变换的两个不同的描述(之所以会不同,是因为选定了不同的基,也就是选定了不同的坐标系),则一定能找到一个非奇异矩阵P,使得A、B之间满足这样的关系:A=P−1BP。线性代数稍微熟一点的读者一下就看出来,这就是相似矩阵的定义。没错,所谓相似矩阵,就是同一个线性变换的不同的描述矩阵。按照这个定义,同一头猪的不同角度的照片也可以成为相似照片。俗了一点,不过能让人明白。而在上面式子里那个矩阵P,其实就是A矩阵所基于的基与B矩阵所基于的基这两组基之间的一个变换关系。
关于这个结论,可以用一种非常直觉的方法来证明(而不是一般教科书上那种形式上的证明),如果有时间的话,我以后在blog里补充这个证明。这个发现太重要了。原来一族相似矩阵都是同一个线性变换的描述啊!难怪这么重要!工科研究生课程中有矩阵论、矩阵分析等课程,其中讲了各种各样的相似变换,比如什么相似标准型,对角化之类的内容,都要求变换以后得到的那个矩阵与先前的那个矩阵式相似的,为什么这么要求?因为只有这样要求,才能保证变换前后的两个矩阵是描述同一个线性变换的。
当然,同一个线性变换的不同矩阵描述,从实际运算性质来看并不是不分好环的。有些描述矩阵就比其他的矩阵性质好得多。这很容易理解,同一头猪的照片也有美丑之分嘛。所以矩阵的相似变换可以把一个比较丑的矩阵变成一个比较美的矩阵,而保证这两个矩阵都是描述了同一个线性变换。这样一来,矩阵作为线性变换描述的一面,基本上说清楚了。但是,事情没有那么简单,或者说,线性代数还有比这更奇妙的性质,那就是,矩阵不仅可以作为线性变换的描述,而且可以作为一组基的描述。而作为变换的矩阵,不但可以把线性空间中的一个点给变换到另一个点去,而且也能够把线性空间中的一个坐标系(基)表换到另一个坐标系(基)去。而且,变换点与变换坐标系,具有异曲同工的效果。线性代数里最有趣的奥妙,就蕴含在其中。理解了这些内容,线性代数里很多定理和规则会变得更加清晰、直觉。
首先来总结一下前面部分的一些主要结论:
1.首先有空间,空间可以容纳对象运动的。一种空间对应一类对象。
2.有一种空间叫线性空间,线性空间是容纳向量对象运动的。
3.运动是瞬时的,因此也被称为变换。
4.矩阵是线性空间中运动(变换)的描述。
5.矩阵与向量相乘,就是实施运动(变换)的过程。
6.同一个变换,在不同的坐标系下表现为不同的矩阵,但是它们的本质是一样的,所以本征值相同。
下面让我们把视力集中到一点以改变我们以往看待矩阵的方式。我们知道,线性空间里的基本对象是向量。
向量是这么表示的:[a1,a2,a3,...,an]。矩阵是这么表示的:a11,a12,a13,...,a1n,a21,a22,a23,...,a2n,...,an1,an2,an3,...,ann不用太聪明,我们就能看出来,矩阵是一组向量组成的。特别的,n维线性空间里的方阵是由n个n维向量组成的。我们在这里只讨论这个n阶的、非奇异的方阵,因为理解它就是理解矩阵的关键,它才是一般情况,而其他矩阵都是意外,都是不得不对付的讨厌状况,大可以放在一边。这里多一句嘴,学习东西要抓住主流,不要纠缠于旁支末节。很可惜我们的教材课本大多数都是把主线埋没在细节中的,搞得大家还没明白怎么回事就先被灌晕了。比如数学分析,明明最要紧的观念是说,一个对象可以表达为无穷多个合理选择的对象的线性和,这个概念是贯穿始终的,也是数学分析的精华。但是课本里自始至终不讲这句话,反正就是让你做吉米多维奇,掌握一大堆解偏题的技巧,记住各种特殊情况,两类间断点,怪异的可微和可积条件(谁还记得柯西条件、迪里赫莱条件...?),最后考试一过,一切忘光光。要我说,还不如反复强调这一个事情,把它深深刻在脑子里,别的东西忘了就忘了,真碰到问题了,再查数学手册嘛,何必因小失大呢?
言归正传,如果一组向量是彼此线性无关的话,那么它们就可以成为度量这个线性空间的一组基,从而事实上成为一个坐标系体系,其中每一个向量都躺在一根坐标轴上,并且成为那根坐标轴上的基本度量单位(长度1)。现在到了关键的一步。看上去矩阵就是由一组向量组成的,而且如果矩阵非奇异的话(我说了,只考虑这种情况),那么组成这个矩阵的那一组向量也就是线性无关的了,也就可以成为度量线性空间的一个坐标系。结论:矩阵描述了一个坐标系。“慢着!”,你嚷嚷起来了,“你这个骗子!你不是说过,矩阵就是运动吗?怎么这会矩阵又是坐标系了?”嗯,所以我说到了关键的一步。我并没有骗人,之所以矩阵又是运动,又是坐标系,那是因为——“运动等价于坐标系变换”。对不起,这话其实不准确,我只是想让你印象深刻。准确的说法是:“对象的变换等价于坐标系的变换”。或者:“固定坐标系下一个对象的变换等价于固定对象所处的坐标系变换。”说白了就是:“运动是相对的。”
让我们想想,达成同一个变换的结果,比如把点(1,1)变到点(2,3)去,你可以有两种做法。第一,坐标系不动,点动,把(1,1)点挪到(2,3)去。第二,点不动,变坐标系,让x轴的度量(单位向量)变成原来的1/2,让y轴的度量(单位向量)变成原先的1/3,这样点还是那个点,可是点的坐标就变成(2,3)了。方式不同,结果一样。从第一个方式来看,那就是把矩阵看成是运动描述,矩阵与向量相乘就是使向量(点)运动的过程。在这个方式下,Ma=b的意思是:“向量a经过矩阵M所描述的变换,变成了向量b。”而从第二个方式来看,矩阵M描述了一个坐标系,姑且也称之为M。那么:Ma=b的意思是:“有一个向量,它在坐标系M的度量下得到的度量结果向量为a,那么它在坐标系I的度量下,这个向量的度量结果是b。”这里的I是指单位矩阵,就是主对角线是1,其他为零的矩阵。而这两个方式本质上是等价的。我希望你务必理解这一点,因为这是本篇的关键。正因为是关键,所以我得再解释一下。在M为坐标系的意义下,如果把M放在一个向量a的前面,形成Ma的样式,我们可以认为这是对向量a的一个环境声明。它相当于是说:“注意了!这里有一个向量,它在坐标系M中度量,得到的度量结果可以表达为a。可是它在别的坐标系里度量的话,就会得到不同的结果。为了明确,我把M放在前面,让你明白,这是该向量在坐标系M中度量的结果。”
那么我们再看孤零零的向量b:b多看几遍,你没看出来吗?它其实不是b,它是:Ib也就是说:“在单位坐标系,也就是我们通常说的直角坐标系I中,有一个向量,度量的结果是b。”而Ma=Ib的意思就是说:“在M坐标系里量出来的向量a,跟在I坐标系里量出来的向量b,其实根本就是一个向量啊!”这哪里是什么乘法计算,根本就是身份识别嘛。从这个意义上我们重新理解一下向量。向量这个东西客观存在,但是要把它表示出来,就要把它放在一个坐标系中去度量它,然后把度量的结果(向量在各个坐标轴上的投影值)按一定顺序列在一起,就成了我们平时所见的向量表示形式。你选择的坐标系(基)不同,得出来的向量的表示就不同。向量还是那个向量,选择的坐标系不同,其表示方式就不同。因此,按道理来说,每写出一个向量的表示,都应该声明一下这个表示是在哪个坐标系中度量出来的。表示的方式,就是Ma,也就是说,有一个向量,在M矩阵表示的坐标系中度量出来的结果为a。
回过头来说变换的问题,我刚才说,“固定坐标系下一个对象的变换等价于固定对象所处的坐标系变换”,那个“固定对象”我们找到了,就是那个向量。但是坐标系的变换呢?我怎么没看见?请看:Ma=Ib我现在要变M为I,怎么变?对了,再前面乘以个M-1,也就是M的逆矩阵。换句话说,你不是有一个坐标系M吗,现在我让它乘以个M-1,变成I,这样一来的话,原来M坐标系中的a在I中一量,就得到b了。我建议你此时此刻拿起纸笔,画画图,求得对这件事情的理解。比如,你画一个坐标系,x轴上的衡量单位是2,y轴上的衡量单位是3,在这样一个坐标系里,坐标为(1,1)的那一点,实际上就是笛卡尔坐标系里的点(2,3)。而让它原形毕露的办法,就是把原来那个坐标系:[2,0,0,3]T 的x方向度量缩小为原来的1/2,而y方向度量缩小为原来的1/3,这样一来坐标系就变成单位坐标系I了。保持点不变,那个向量现在就变成了(2, 3)了。 怎么能够让“x方向度量缩小为原来的1/2,而y方向度量缩小为原来的1/3”呢?就是让原坐标系:[2,0,0,3] 被矩阵[1/2,0,0,1/3]T 左乘。而这个矩阵就是原矩阵的逆矩阵。
下面我们得出一个重要的结论:“对坐标系施加变换的方法,就是让表示那个坐标系的矩阵与表示那个变化的矩阵相乘。”再一次的,矩阵的乘法变成了运动的施加。只不过,被施加运动的不再是向量,而是另一个坐标系。如果你觉得你还搞得清楚,请再想一下刚才已经提到的结论,矩阵MxN,一方面表明坐标系N在运动M下的变换结果,另一方面,把M当成N的前缀,当成N的环境描述,那么就是说,在M坐标系度量下,有另一个坐标系N。这个坐标系N如果放在I坐标系中度量,其结果为坐标系MxN。
在这里,我实际上已经回答了一般人在学习线性代数是最困惑的一个问题,那就是为什么矩阵的乘法要规定成这样。简单地说,是因为:
1.从变换的观点看,对坐标系N施加M变换,就是把组成坐标系N的每一个向量施加M变换。
2.从坐标系的观点看,在M坐标系中表现为N的另一个坐标系,这也归结为,对N坐标系基的每一个向量,把它在I坐标系中的坐标找出来,然后汇成一个新的矩阵。
3.至于矩阵乘以向量为什么要那样规定,那是因为一个在M中度量为a的向量,如果想要恢复在I中的真像,就必须分别与M中的每一个向量进行內积运算。
我把这个结论的推导留给感兴趣的朋友吧。综合以上,矩阵的乘法就得那么规定,一切有根有据,绝不是哪个神经病胡思乱想出来的。我们伟大的线性代数课本上说的矩阵定义,是无比正确的:“矩阵就是由m行n列数放在一起组成的数学对象。”好了,这基本上就是我想说的全部了。
本文原文是孟岩在csdn上发表的三篇博客:理解矩阵(一),理解矩阵(二), 理解矩阵(三)
我对这篇文章的自己做的总结:
1、空间的定义都是先定义一个集合,然后在这个集合上定义一些概念和规则,就成了某某空间;“容纳运动(变换)是空间的本质!!!”
2、空间中的运动为线性变换便称为线性空间、拓扑变换便称为拓扑空间、仿射变换就称为仿射空间;一般我们说的空间有三个基本特征:
(1)空间中点的表示形式;
(2)空间中点的相对关系;
(3)空间中点的运动形式;
4、向量空间相对于线性空间还要满足内积的定义;
5、所谓相似矩阵,就是同一个线性变换的不同的描述矩阵;
3、线性空间两个最基本特征:
(1)空间中点的表示形式:线性空间中的任何一个对象,通过选取基和坐标的方法,都可以表达为向量的形式;
(2)空间中点的运动形式:线性变换(不是微积分中的连续运动,而是瞬间发生的变化,所以这里称为变换),都用矩阵来表示,矩阵的本质就是运动的描述;
继续深入,“运动是相对的”,对象的变换等价于坐标系的变换,而对于向量,它是客观存在的,要把它表示出来,需要把它放在一个坐标系中去度量;对于M*a=b这个式子,一种解释是在同一种坐标系中,向量a经过变换M运动到b处;第二种解释是在某一种坐标系下(比如称为A)的a,A坐标系经过M变换变换到B坐标系,得到的向量b是在B坐标系下度量的结果;
而我们学过的矩阵论的那些知识实际就是在研究各种变换以及它们的性质!
URI URL URN
- 作者: TheBadZhang
- 时间:
- 分类: 编程,学习
- 评论
曾经我天真的以为URI和URL是一样的,只是不同叫法而已,然后某一天有人告诉我这两个不一样,so我发现是时候好好研究一下这两个概念了。
URI:Uniform Resource Identifier,统一资源标识符
URL:Uniform Resource Location统一资源定位符
它们有什么关系
URI是一个用于标识互联网资源名称的字符串。 该种标识允许用户对网络中(一般指万维网)的资源通过特定的协议进行交互操作。URI的最常见的形式是统一资源定位符(URL),经常指定为非正式的网址。更罕见的用法是统一资源名称(URN),其目的是通过提供一种途径。用于在特定的命名空间资源的标识,以补充网址。
通俗地说,URL和URN是URI的子集,URI属于URL更高层次的抽象,一种字符串文本标准。
三者关系如下图:

图示
有什么区别
上面虽然大概介绍了这两者的区别,不过感觉还是有些模糊,下面着重研究区别。
首先,URI,是统一资源标识符,用来唯一的标识一个资源。而URL是统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。而URN,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com。也就是说,URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI;
URL是URI的一种(通过那个图就看的出来吧)。但也不是所有的URI都是URL哦,就好像蝴蝶都会飞,但会飞的可不都是蝴蝶啊!
让URI能成为URL的当然就是那个“访问机制”,“网络位置”。e.g. http://
or ftp://.。URN是唯一标识的一部分,就是一个特殊的名字。
下面就来看看例子吧,当来也是来自权威的RFC:
ftp://ftp.is.co.za/rfc/rfc1808.txt (also a URL because of the protocol)
http://www.ietf.org/rfc/rfc2396.txt (also a URL because of the protocol)
ldap://[2001:db8::7]/c=GB?objectClass?one (also a URL because of the protocol)
mailto:John.Doe@example.com (also a URL because of the protocol)
news:comp.infosystems.www.servers.unix (also a URL because of the protocol)
tel:+1-816-555-1212
telnet://192.0.2.16:80/ (also a URL because of the protocol)
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
这些全都是URI, 其中有些是URL. 哪些? 就是那些提供了访问机制的.
各自的组成
- URI
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的;
URI一般由三部组成
①访问资源的命名机制
②存放资源的主机名
③资源自身的名称,由路径表示,着重强调于资源。
- URL
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL一般由三部组成
①协议(或称为服务方式)
②存有该资源的主机IP地址(有时也包括端口号)
③主机资源的具体地址。如目录和文件名等
现在,你明白了了吗,欢迎提出意见和补充哦
作者:daixinye
链接:https://www.zhihu.com/question/21950864/answer/154309494
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。拿人做例子,假设这个世界上所有人的名字都不能重复,那么名字就是URI的一个实例,通过名字这个字符串就可以标识出唯一的一个人。现实当中名字当然是会重复的,所以身份证号才是URI,通过身份证号能让我们能且仅能确定一个人。那统一资源定位符URL是什么呢。也拿人做例子然后跟HTTP的URL做类比,就可以有:动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人可以看到,这个字符串同样标识出了唯一的一个人,起到了URI的作用,所以URL是URI的子集。URL是以描述人的位置来唯一确定一个人的。在上文我们用身份证号也可以唯一确定一个人。对于这个在杭州的张三,我们也可以用:身份证号:123456789来标识他。所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URl的一种实现,而URL就是用定位的方式实现的URI。回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适,不过这样子的话还得想办法找到这个资源咯…发布于 2017-03-29赞同 98357 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续张晓杰程序员101 人赞同了该回答URI 在于I(Identifier)是统一资源标示符,可以唯一标识一个资源。URL在于Locater,一般来说(URL)统一资源定位符,可以提供找到该资源的路径,比如http://www.zhihu.com/question/21950864,但URL又是URI,因为它可以标识一个资源,所以URL又是URI的子集。举个是个URI但不是URL的例子:urn:isbn:0-486-27557-4,这个是一本书的isbn,可以唯一标识这本书,更确切说这个是URN。总的来说,locators are also identifiers, so every URL is also a URI, but there are URIs which are not URLs.编辑于 2014-08-06赞同 1016 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续wuxinliulei做好自己136 人赞同了该回答从JDK1.5开始,http://java.net包对统一资源定位符(uniform resource locator URL)和统一资源标识符(uniform resource identifier URI)作了非常明确的区分。(1)URI是个纯粹的句法结构,用于指定标识Web资源的字符串的各个不同部分。URL是URI的一个特例,它包含了定位Web资源的足够信息。其他URI,比如mailto:cay@horstman.com 则不属于定位符,因为根据该标识符无法定位任何资源。URI 是统一资源标识符,而 URL 是统一资源定位符。因此,笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。 URI 和 URL 概念上的不同反映在此类和 URL 类的不同中。 此类的实例代表由 RFC 2396 定义的语法意义上的一个 URI 引用。URI 可以是绝对的,也可以是相对的。对 URI 字符串按照一般语法进行解析,不考虑它所指定的方案(如果有)不对主机(如果有)执行查找,也不构造依赖于方案的流处理程序。相等性、哈希计算以及比较都严格地根据实例的字符内容进行定义。换句话说,一个 URI 实例和一个支持语法意义上的、依赖于方案的比较、规范化、解析和相对化计算的结构化字符串差不多。 作为对照,URL 类的实例代表了 URL 的语法组成部分以及访问它描述的资源所需的信息。URL 必须是绝对的,即它必须始终指定一个方案。URL 字符串按照其方案进行解析。通常会为 URL 建立一个流处理程序,实际上无法为未提供处理程序的方案创建一个 URL 实例。相等性和哈希计算依赖于方案和主机的 Internet 地址(如果有);没有定义比较。换句话说,URL 是一个结构化字符串,它支持解析的语法运算以及查找主机和打开到指定资源的连接之类的网络 I/O 操作。在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。相反的是,URL类可以打开一个到达资源的流。因此URL类只能作用于那些 Java类库知道该如何处理的模式,例如http:,https:,ftp:,本地文件系统(file:),和Jar文件(jar:)。URI—Uniform Resource Identifier通用资源标志符Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的URI一般由三部组成①访问资源的命名机制②存放资源的主机名③资源自身的名称,由路径表示,着重强调于资源。URL—Uniform Resource Location统一资源定位符URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成①协议(或称为服务方式)②存有该资源的主机IP地址(有时也包括端口号)③主机资源的具体地址。如目录和文件名等应用:一 、 URI比如在JDK中sun公司提供的简易HttpServer实现中public void handle(final HttpExchange exchange)throws Exception方法中,根据exchange对象可以拿到访问Http请求的URI对象,ps:http://127.0.0.1:8080/cmd_helloworld/?name=guowuxin此时URI uri = exchange.getRequestURI();通过uri可以拿到连接的各部分内容: uri.getPath() --------------------> /cmd_helloworld 注意有斜杠uri.getQuery()----------------------> name=guowuxin当然如果是post请求,请求内容在请求body当中二、 URL 上面说了,URL 是一个结构化字符串,它支持解析的语法运算以及查找主机和打开到指定资源的连接之类的网络 I/O 操作。重要的,URL不仅仅可以进行语法解析运算,还可以查找主机,并且打开指定资源的连接进行网络IO操作。介绍URL类的两个重要方法openStream() 打开到此 URL 的连接并返回一个用于从该连接读入的 InputStream。openConnection() 返回一个 URLConnection 对象,它表示到 URL 所引用的远程对象的连接。 URL url = new URL("http://www.baidu.com");
InputStream in = url.openStream();
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while ((len = in.read(buffer)) != -1)
{
output.write(buffer, 0, len);}
System.err.println(new String(output.toByteArray()));上面的程序通过openStream()方法获取访问URL获取的输入流,从而读取响应内容,ps响应内容是过滤掉响应头了的。openConnection()方法就可以getOutputStream()以及 getInputStream()可以更灵活的进行request和response编辑于 2019-02-15赞同 13612 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续Octocat52 人赞同了该回答URI可被视为定位符(URL),名称(URN)或两者兼备。统一资源名(URN)如同一个人的名称,而统一资源定位符(URL)代表一个人的住址。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。URL是一种URI,它标识一个互联网资源,并指定对其进行操作或获取该资源的方法。可能通过对主要访问手段的描述,也可能通过网络“位置”进行标识。例如,http://www.wikipedia.org/这个URL,标识一个特定资源(首页)并表示该资源的某种形式(例如以编码字符表示的,首页的HTML代码)是可以通过HTTP协议从http://www.wikipedia.org这个网络主机获得的。URN是基于某命名空间通过名称指定资源的URI。人们可以通过URN来指出某个资源,而无需指出其位置和获得方式。资源无需是基于互联网的。例如,URN urn:isbn:0-395-36341-1 指定标识系统(即国际标准书号ISBN)和某资源在该系统中的唯一表示的URI。它可以允许人们在不指出其位置和获得方式的情况下谈论这本书。引用自https://zh.wikipedia.org/wiki/%E7%BB%9F%E4%B8%80%E8%B5%84%E6%BA%90%E6%A0%87%E5%BF%97%E7%AC%A6简单理解是这样的:理解URI和URL的区别,我们引入URN这个概念。URI = Universal Resource Identifier 统一资源标志符URL = Universal Resource Locator 统一资源定位符URN = Universal Resource Name 统一资源名称这三者的关系如下图: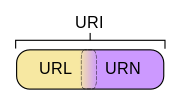 也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。
也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。
同样的,URN(统一资源名称)也是URI的一个子集,目前没有大规模运用。PS:
URI是一个字符串格式规范 并没有指定它的用途URL是资源定位的规范 包括网址 ftp服务器 文件路径编辑于 2016-08-30赞同 848 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续张磊不知学之14 人赞同了该回答Mozilla官方解释的特别好。标识互联网上的内容发布于 2017-10-13赞同 14添加评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续高洪涛习惯决定命运6 人赞同了该回答有篇感觉还不错的文章,我翻译了下,有兴趣的可以看下:[译]URL和URI的区别发布于 2015-08-12赞同 6添加评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续陆垠宇韶华散尽春已去 河风吹老少年郎.(●'◡'●)7 人赞同了该回答URI字段:指浏览器输入域名/开始后的内容,如http://www.abc.com.cn/aaa,URI字段为/aaa;HOST字段:指浏览器输入地址http://之后URI/之前的内容,如http://www.abc.com.cn/cba/aaa.php HOST字段为www.abc.comURL-HOST=URI.(●'◡'●)发布于 2018-01-31赞同 72 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续猫头佛PHP/运维/健身/读书2 人赞同了该回答参考了 @daixinye 的答案,又看了一些资料,自己总结了一下,希望有帮助吧。画图说明URI(Uniform Resource Identifier,统一资源标识符):一个资源的唯一标识,可以是一个名字、一串编号、一个URL(说明URL是一种URI)......URL(Uniform Resource Locator,统一资源定位符):一个资源的网络地址格式一般是:网络协议://域名/子目录[/子目录.....]/文件名[.文件名后缀]例子https://www.zhihu.com/question/21950864http://example.com/mypage.htmlftp://example.com/download.zipmailto:user@example.comfile:///home/user/file.txttel:1-888-555-5555http://example.com/resource?fo…/other/link.html (相对URL,仅在另一个URL的语境下有用)两者关系URI负责识别,URL负责定位URL是URI的子集(URL一定是URI,但URI不一定是URL)URI是一个唯一字符串URL是一个表示位置(或地址)的唯一字符串举例说明我要找到这个骚扰如花的油腻大叔!谁能提供他的信息?普通URI的告知方式他的身份证号是442736199706268734 或者这是他的指纹图案 或者这是他的DNA检测报告URL(一种特殊的URI)的告知方式动物住址协议://地球/中国/广东省/深圳市/南山区/XX小区/X栋X座24楼/5号座位/陈狗蛋.人(例子参考:HTTP 协议中 URI 和 URL 有什么区别?)引申领域:URI还有其他种类,类似于URN、URC......这些平时接触不多,有兴趣的可以自己另外寻找文章了解一下画图说明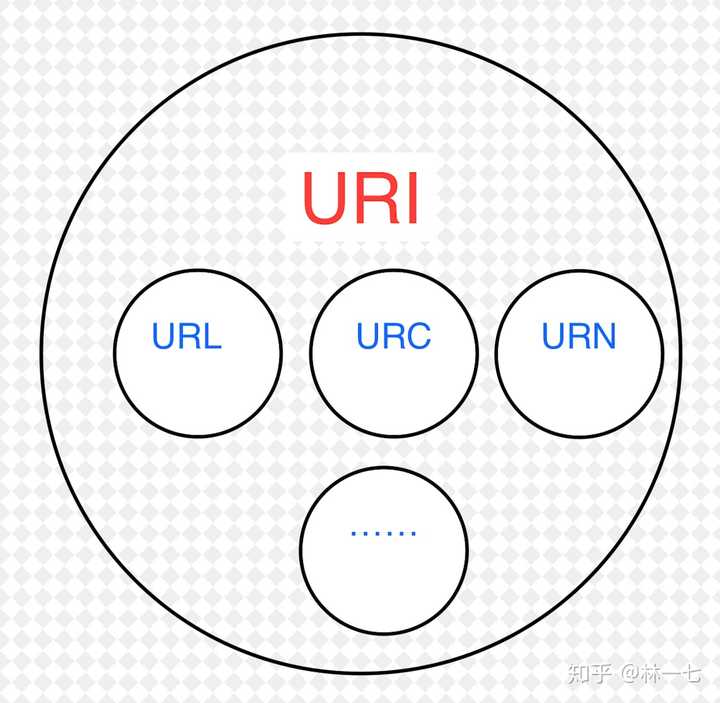 编辑于 2019-12-11
编辑于 2019-12-11
《51 单片机快速入门》读书笔记
- 作者: TheBadZhang
- 时间:
- 分类: 编程,学习
- 评论
51 单片机快速入门
[TOC]
keil uVision5
第一步,点亮你的 LED
电源
晶振
复位电路
特殊功能寄存器
程序下载
第二步,硬件基础知识
电磁干扰
三极管
三八译码器
流水灯
定时器与数码管
中断与数码管动态显示
矩阵 LED
按键
步进电机与蜂鸣器
实例练习
UART串口通信
1602 液晶
1602 与 串口
i2c和e2prom
ds1302
红外通信
模数转换和数模转换
RS-485 与 modbus协议
多功能电子钟
单片机开发常用工具
万用表
示波器
逻辑分析仪
【转载】CppTemplateTutorial
- 作者: TheBadZhang
- 时间:
- 分类: 编程,学习,转载
- 评论
C++ Template 进阶指南
[TOC]
0. 前言
0.1 C++另类简介:比你用的复杂,但比你想的简单
C++似乎从它为世人所知的那天开始便成为天然的话题性编程语言。在它在周围有着形形色色的赞美与贬低之词。当我在微博上透露欲写此文的意愿时,也收到了很多褒贬不一的评论。作为一门语言,能拥有这么多使用并恨着它、使用并畏惧它的用户,也算是语言丛林里的奇观了。
C++之所以变成一门层次丰富、结构多变、语法繁冗的语言,是有着多层次的原因的。Bjarne在《The Design and Evolution of C++》一书中,详细的解释了C++为什么会变成如今(C++98/03)的模样。这本书也是我和陈梓瀚一直对各位已经入门的新手强烈推荐的一本书。通过它你多少可以明白,C++的诸多语法要素之所以变成如今的模样,实属迫不得已。
模板作为C++中最有特色的语言特性,它堪称玄学的语法和语义,理所应当的成为初学者的梦魇。甚至很多工作多年的人也对C++的模板部分保有充分的敬畏。在多数的编码标准中,Template俨然和多重继承一样,成为了一般程序员(非程序库撰写者)的禁区。甚至运用模板较多的Boost,也成为了“众矢之的”。
但是实际上C++模板远没有想象的那么复杂。我们只需要换一个视角:在C++03的时候,模板本身就可以独立成为一门“语言”。它有“值”,有“函数”,有“表达式”和“语句”。除了语法比较蹩脚外,它既没有指针也没有数组,更没有C++里面复杂的继承和多态。可以说,它要比C语言要简单的多。如果我们把模板当做是一门语言来学习,那只需要花费学习OO零头的时间即可掌握。按照这样的思路,可以说在各种模板书籍中出现的多数技巧,都可以被轻松理解。
简单回顾一下模板的历史。87年的时候,泛型(Generic Programming)便被纳入了C++的考虑范畴,并直接导致了后来模板语法的产生。可以说模板语法一开始就是为了在C++中提供泛型机制。92年的时候,Alexander Stepanov开始研究利用模板语法制作程序库,后来这一程序库发展成STL,并在93年被接纳入标准中。
此时不少人以为STL已经是C++模板的集大成之作,C++模板技止于此。但是在95年的《C++ Report》上,John Barton和Lee Nackman提出了一个矩阵乘法的模板示例。可以说元编程在那个时候开始被很多人所关注。自此篇文章发表之后,很多大牛都开始对模板产生了浓厚的兴趣。其中对元编程技法贡献最大的当属Alexandrescu的《Modern C++ Design》及模板程序库Loki。这一2001年发表的图书间接地导致了模板元编程库的出现。书中所使用的Typelist等泛型组件,和Policy等设计方法令人耳目一新。但是因为全书用的是近乎Geek的手法来构造一切设施,因此使得此书阅读起来略有难度。
2002年出版的另一本书《C++ Templates》,可以说是在Template方面的集大成之作。它详细阐述了模板的语法、提供了和模板有关的语言细节信息,举了很多有代表性例子。但是对于模板新手来说,这本书细节如此丰富,让他们随随便便就打了退堂鼓缴械投降。
本文的写作初衷,就是通过“编程语言”的视角,介绍一个简单、清晰的“模板语言”。我会尽可能地将模板的诸多要素连串起来,用一些简单的例子帮助读者学习这门“语言”,让读者在编写、阅读模板代码的时候,能像 if(exp) { dosomething(); }一样的信手拈来,让“模板元编程”技术成为读者牢固掌握、可举一反三的有用技能。
0.2 适宜读者群
因为本文并不是用于C++入门,例子中也多少会牵涉一些其它知识,因此如果读者能够具备以下条件,会读起来更加轻松:
- 熟悉C++的基本语法;
- 使用过STL;
- 熟悉一些常用的算法,以及递归等程序设计方法。
此外,尽管第一章会介绍一些Template的基本语法,但是还是会略显单薄。因此也希望读者能对C++ Template最基本语法形式有所了解和掌握;如果会编写基本的模板函数和模板类那就更好了。
诚如上节所述,本文并不是《C++ Templates》的简单重复,与《Modern C++ Design》交叠更少。从知识结构上,我建议大家可以先读本文,再阅读《C++ Templates》获取更丰富的语法与实现细节,以更进一步;《Modern C++ Design》除了元编程之外,还有很多的泛型编程示例,原则上泛型编程的部分与我所述的内容交叉不大,读者在读完1-3章了解模板的基本规则之后便可阅读《MCD》的相应章节;元编程部分(如Typelist)建议在阅读完本文之后再行阅读,或许会更易理解。
0.3 版权
本文是随写随即同步到Github上,因此在行文中难免会遗漏引用。本文绝大部分内容应是直接承出我笔,但是也不定会有他山之石。所有指涉内容我会尽量以引号框记,或在上下文和边角注记中标示,如有遗漏烦请不吝指出。
全文所有为我所撰写的部分,作者均保留所有版权。如果有需要转帖或引用,还请注明出处并告知于我。
0.4 推荐编译环境
C++编译器众多,且对模板的支持可能存在细微差别。如果没有特别强调,本书行文过程中,使用了下列编译器来测试文中提供的代码和示例:
- Clang 3.7 (x86)
- Visual Studio 2015 Update 3
- GCC 7 (x86, snapshot)
此外,部分复杂实例我们还在文中提供了在线的编译器预览以方便大家阅读和测试。在线编译器参见: gcc.godbolt.org。
一些示例中用到的特性所对应的C++标准:
| 特性 | 标准 |
|---|---|
| std::decay_t | C++ 14 |
0.5 体例
0.5.1 示例代码
void SampleCode() {
// 这是一段示例代码
}0.5.2 引用
引用自C++标准:
1.1.2/1 这是一段引用或翻译自标准的文字
引用自其他图书:
《书名》
这是一段引用或翻译自其他图书的文字
0.6 意见、建议、喷、补遗、写作计划
需增加:
- 模板的使用动机。
- 增加“如何使用本文”一节。本节将说明全书的体例(强调字体、提示语、例子的组织),所有的描述、举例、引用在重审时将按照体例要求重新组织。
- 除了用于描述语法的例子外,其他例子将尽量赋予实际意义,以方便阐述意图。
- 在合适的章节完整叙述模板的类型推导规则。Parameter-Argument, auto variable, decltype, decltype(auto)
- 在函数模板重载和实例化的部分讲述ADL。
- 变参模板处应当按照标准(Argument Packing/Unpacking)来讲解。
建议:
- 比较模板和函数的差异性
- 蓝色:C++14 Return type deduction for normal functions 的分析
1. Template的基本语法
1.1 Template Class基本语法
1.1.1 Template Class的与成员变量定义
我们来回顾一下最基本的Template Class声明和定义形式:
Template Class声明:
template <typename T> class ClassA;Template Class定义:
template <typename T> class ClassA
{
T member;
};template 是C++关键字,意味着我们接下来将定义一个模板。和函数一样,模板也有一系列参数。这些参数都被囊括在template之后的< >中。在上文的例子中, typename T便是模板参数。回顾一下与之相似的函数参数的声明形式:
void foo(int a);T则可以类比为函数形参a,这里的“模板形参”T,也同函数形参一样取成任何你想要的名字;typename则类似于例子中函数参数类型int,它表示模板参数中的T将匹配一个类型。除了 typename 之外,我们在后面还要讲到,整型也可以作为模板的参数。
在定义完模板参数之后,便可以定义你所需要的类。不过在定义类的时候,除了一般类可以使用的类型外,你还可以使用在模板参数中使用的类型 T。可以说,这个 T是模板的精髓,因为你可以通过指定模板实参,将T替换成你所需要的类型。
例如我们用ClassA<int>来实例化模板类ClassA,那么ClassA<int>可以等同于以下的定义:
// 注意:这并不是有效的C++语法,只是为了说明模板的作用
typedef class {
int member;
} ClassA<int>;可以看出,通过模板参数替换类型,可以获得很多形式相同的新类型,有效减少了代码量。这种用法,我们称之为“泛型”(Generic Programming),它最常见的应用,即是STL中的容器模板类。
1.1.2 模板的使用
对于C++来说,类型最重要的作用之一就是用它去产生一个变量。例如我们定义了一个动态数组(列表)的模板类vector,它对于任意的元素类型都具有push_back和clear的操作,我们便可以如下定义这个类:
template <typename T>
class vector
{
public:
void push_back(T const&);
void clear();
private:
T* elements;
};此时我们的程序需要一个整型和一个浮点型的列表,那么便可以通过以下代码获得两个变量:
vector<int> intArray;
vector<float> floatArray;此时我们就可以执行以下的操作,获得我们想要的结果:
intArray.push_back(5);
floatArray.push_back(3.0f);变量定义的过程可以分成两步来看:第一步,vector<int>将int绑定到模板类vector上,获得了一个“普通的类vector<int>”;第二步通过“vector
与“普通的类”不同,模板类是不能直接用来定义变量的。例如:
vector unknownVector; // 错误示例这样就是错误的。我们把通过类型绑定将模板类变成“普通的类”的过程,称之为模板实例化(Template Instantiate)。实例化的语法是:
模板名 < 模板实参1 [,模板实参2,...] >看几个例子:
vector<int>
ClassA<double>
template <typename T0, typename T1> class ClassB
{
// Class body ...
};
ClassB<int, float>当然,在实例化过程中,被绑定到模板参数上的类型(即模板实参)需要与模板形参正确匹配。
就如同函数一样,如果没有提供足够并匹配的参数,模板便不能正确的实例化。
1.1.3 模板类的成员函数定义
由于C++11正式废弃“模板导出”这一特性,因此在模板类的变量在调用成员函数的时候,需要看到完整的成员函数定义。因此现在的模板类中的成员函数,通常都是以内联的方式实现。
例如:
template <typename T>
class vector
{
public:
void clear()
{
// Function body
}
private:
T* elements;
};当然,我们也可以将vector<T>::clear的定义部分放在类型之外,只不过这个时候的语法就显得蹩脚许多:
template <typename T>
class vector
{
public:
void clear(); // 注意这里只有声明
private:
T* elements;
};
template <typename T>
void vector<T>::clear() // 函数的实现放在这里
{
// Function body
}函数的实现部分看起来略微拗口。我第一次学到的时候,觉得
void vector::clear()
{
// Function body
}这样不就行了吗?但是简单想就会知道,clear里面是找不到泛型类型T的符号的。
因此,在成员函数实现的时候,必须要提供模板参数。此外,为什么类型名不是vector而是vector<T>呢?
如果你了解过模板的偏特化与特化的语法,应该能看出,这里的vector
综上,正确的成员函数实现如下所示:
template <typename T> // 模板参数
void vector<T> /*看起来像偏特化*/ ::clear() // 函数的实现放在这里
{
// Function body
}1.2 Template Function的基本语法
1.2.1 Template Function的声明和定义
模板函数的语法与模板类基本相同,也是以关键字template和模板参数列表作为声明与定义的开始。模板参数列表中的类型,可以出现在参数、返回值以及函数体中。比方说下面几个例子
template <typename T> void foo(T const& v);
template <typename T> T foo();
template <typename T, typename U> U foo(T const&);
template <typename T> void foo()
{
T var;
// ...
}无论是函数模板还是类模板,在实际代码中看起来都是“千变万化”的。这些“变化”,主要是因为类型被当做了参数,导致代码中可以变化的部分更多了。
归根结底,模板无外乎两点:
- 函数或者类里面,有一些类型我们希望它能变化一下,我们用标识符来代替它,这就是“模板参数”;
- 在需要这些类型的地方,写上相对应的标识符(“模板参数”)。
当然,这里的“可变”实际上在代码编译好后就固定下来了,可以称之为编译期的可变性。
这里多啰嗦一点,主要也是想告诉大家,模板其实是个很简单的东西。
下面这个例子,或许可以帮助大家解决以下两个问题:
- 什么样的需求会使用模板来解决?
- 怎样把脑海中的“泛型”变成真正“泛型”的代码?
举个例子:generic typed function ‘add’在我遇到的朋友中,即便如此对他解释了模板,即便他了解了模板,也仍然会对模板产生畏难情绪。毕竟从形式上来说,模板类和模板函数都要较非模板的版本更加复杂,阅读代码所需要理解的内容也有所增多。
如何才能克服这一问题,最终视模板如平坦代码呢?
答案只有一个:无他,唯手熟尔。
在学习模板的时候,要反复做以下的思考和练习:
- 提出问题:我的需求能不能用模板来解决?
- 怎么解决?
- 把解决方案用代码写出来。
- 如果失败了,找到原因。是知识有盲点(例如不知道怎么将
T&转化成T),还是不可行(比如试图利用浮点常量特化模板类,但实际上这样做是不可行的)?
通过重复以上的练习,应该可以对模板的语法和含义都有所掌握。如果提出问题本身有困难,或许下面这个经典案例可以作为你思考的开始:
- 写一个泛型的数据结构:例如,线性表,数组,链表,二叉树;
- 写一个可以在不同数据结构、不同的元素类型上工作的泛型函数,例如求和;
当然和“设计模式”一样,模板在实际应用中,也会有一些固定的需求和解决方案。比较常见的场景包括:泛型(最基本的用法)、通过类型获得相应的信息(型别萃取)、编译期间的计算、类型间的推导和变换(从一个类型变换成另外一个类型,比如boost::function)。这些本文在以后的章节中会陆续介绍。
1.2.2 模板函数的使用
我们先来看一个简单的函数模板,两个数相加:
template <typename T> T Add(T a, T b)
{
return a + b;
}函数模板的调用格式是:
函数模板名 < 模板参数列表 > ( 参数 )例如,我们想对两个 int 求和,那么套用类的模板实例化方法,我们可以这么写:
int a = 5;
int b = 3;
int result = Add<int>(a, b);这时我们等于拥有了一个新函数:
int Add<int>(int a, int b) { return a + b; }这时在另外一个偏远的程序角落,你也需要求和。而此时你的参数类型是 float ,于是你写下:
Add<float>(a, b);一切看起来都很完美。但如果你具备程序员的最佳美德——懒惰——的话,你肯定会这样想,我在调用 Add<int>(a, b) 的时候, a 和 b 匹配的都是那个 T。编译器就应该知道那个 T 实际上是 int 呀?为什么还要我多此一举写 Add<int> 呢?
唔,我想说的是,编译器的作者也是这么想的。所以实际上你在编译器里面写下以下片段:
int a = 5;
int b = 3;
int result = Add(a, b);编译器会心领神会地将 Add 变成 Add<int>。但是编译器不能面对模棱两可的答案。比如你这么写的话呢?
int a = 5;
char b = 3;
int result = Add(a, b);第一个参数 a 告诉编译器,这个 T 是 int。编译器点点头说,好。但是第二个参数 b 不高兴了,告诉编译器说,你这个 T,其实是 char。
两个参数各自指导 T 的类型,编译器就不知道怎么做了。在Visual Studio 2012下,会有这样的提示:
error C2782: 'T _1_2_2::Add(T,T)' : template parameter 'T' is ambiguous好吧,"ambiguous",这个提示再明确不过了。
不过,只要你别逼得编译器精神分裂的话,编译器其实是非常聪明的,它可以从很多的蛛丝马迹中,猜测到你真正的意图,有如下面的例子:
template <typename T> class A {};
template <typename T> T foo( A<T> v );
A<int> v;
foo(v); // 它能准确地猜到 T 是 int.咦,编译器居然绕过了A这个外套,猜到了 T 匹配的是 int。编译器是怎么完成这一“魔法”的,我们暂且不表,2.2节时再和盘托出。
下面轮到你的练习时间了。你试着写了很多的例子,但是其中一个你还是犯了疑惑:
float data[1024];
template <typename T> T GetValue(int i)
{
return static_cast<T>(data[i]);
}
float a = GetValue(0); // 出错了!
int b = GetValue(1); // 也出错了!为什么会出错呢?你仔细想了想,原来编译器是没办法去根据返回值推断类型的。函数调用的时候,返回值被谁接受还不知道呢。如下修改后,就一切正常了:
float a = GetValue<float>(0);
int b = GetValue<int>(1);嗯,是不是so easy啊?嗯,你又信心满满的做了一个练习:
你要写一个模板函数叫 c_style_cast,顾名思义,执行的是C风格的转换。然后出于方便起见,你希望它能和 static_cast 这样的内置转换有同样的写法。于是你写了一个use case。
DstT dest = c_style_cast<DstT>(src);根据调用形式你知道了,有 DstT 和 SrcT 两个模板参数。参数只有一个, src,所以函数的形参当然是这么写了: (SrcT src)。实现也很简单, (DstT)v。
我们把手上得到的信息来拼一拼,就可以编写自己的函数模板了:
template <typename SrcT, typename DstT> DstT c_style_cast(SrcT v)
{
return (DstT)(v);
}
int v = 0;
float i = c_style_cast<float>(v);嗯,很Easy嘛!我们F6一下…咦!这是什么意思!
error C2783: 'DstT _1_2_2::c_style_cast(SrcT)' : could not deduce template argument for 'DstT'然后你仔细的比较了一下,然后发现 … 模板参数有两个,而参数里面能得到的只有 SrcT 一个。结合出错信息看来关键在那个 DstT 上。这个时候,你死马当活马医,把模板参数写完整了:
float i = c_style_cast<int, float>(v);嗯,很顺利的通过了。难道C++不能支持让参数推导一部分模板参数吗?
当然是可以的。只不过在部分推导、部分指定的情况下,编译器对模板参数的顺序是有限制的:先写需要指定的模板参数,再把能推导出来的模板参数放在后面。
在这个例子中,能推导出来的是 SrcT,需要指定的是 DstT。把函数模板写成下面这样就可以了:
template <typename DstT, typename SrcT> DstT c_style_cast(SrcT v) // 模板参数 DstT 需要人肉指定,放前面。
{
return (DstT)(v);
}
int v = 0;
float i = c_style_cast<float>(v); // 形象地说,DstT会先把你指定的参数吃掉,剩下的就交给编译器从函数参数列表中推导啦。1.3 整型也可是Template参数
模板参数除了类型外(包括基本类型、结构、类类型等),也可以是一个整型数(Integral Number)。这里的整型数比较宽泛,包括布尔型,不同位数、有无符号的整型,甚至包括指针。我们将整型的模板参数和类型作为模板参数来做一个对比:
template <typename T> class TemplateWithType;
template <int V> class TemplateWithValue;我想这个时候你也更能理解 typename 的意思了:它相当于是模板参数的“类型”,告诉你 T 是一个 typename。
按照C++ Template最初的想法,模板不就是为了提供一个类型安全、易于调试的宏吗?有类型就够了,为什么要引入整型参数呢?考虑宏,它除了代码替换,还有一个作用是作为常数出现。所以整型模板参数最基本的用途,也是定义一个常数。例如这段代码的作用:
template <typename T, int Size> struct Array
{
T data[Size];
};
Array<int, 16> arr;便相当于下面这段代码:
class IntArrayWithSize16
{
int data[16]; // int 替换了 T, 16 替换了 Size
};
IntArrayWithSize16 arr;其中有一点需要注意,因为模板的匹配是在编译的时候完成的,所以实例化模板的时候所使用的参数,也必须要在编译期就能确定。例如以下的例子编译器就会报错:
template <int i> class A {};
void foo()
{
int x = 3;
A<5> a; // 正确!
A<x> b; // error C2971: '_1_3::A' : template parameter 'i' : 'x' : a local variable cannot be used as a non-type argument
}因为x不是一个编译期常量,所以 A<x> 就会告诉你,x是一个局部变量,不能作为一个模板参数出现。
嗯,这里我们再来写几个相对复杂的例子:
template <int i> class A
{
public:
void foo(int)
{
}
};
template <uint8_t a, typename b, void* c> class B {};
template <bool, void (*a)()> class C {};
template <void (A<3>::*a)(int)> class D {};
template <int i> int Add(int a) // 当然也能用于函数模板
{
return a + i;
}
void foo()
{
A<5> a;
B<7, A<5>, nullptr> b; // 模板参数可以是一个无符号八位整数,可以是模板生成的类;可以是一个指针。
C<false, &foo> c; // 模板参数可以是一个bool类型的常量,甚至可以是一个函数指针。
D<&A<3>::foo> d; // 丧心病狂啊!它还能是一个成员函数指针!
int x = Add<3>(5); // x == 8。因为整型模板参数无法从函数参数获得,所以只能是手工指定啦。
}
template <float a> class E {}; // ERROR: 别闹!早说过只能是整数类型的啦!当然,除了单纯的用作常数之外,整型参数还有一些其它的用途。这些“其它”用途最重要的一点是让类型也可以像整数一样运算。《Modern C++ Design》给我们展示了很多这方面的例子。不过你不用急着去阅读那本天书,我们会在做好足够的知识铺垫后,让你轻松学会这些招数。
1.4 模板形式与功能是统一的
第一章走马观花的带着大家复习了一下C++ Template的基本语法形式,也解释了包括 typename 在内,类/函数模板写法中各个语法元素的含义。形式是功能的外在体现,介绍它们也是为了让大家能理解到,模板之所以写成这种形式是有必要的,而不是语言的垃圾成分。
从下一章开始,我们便进入了更加复杂和丰富的世界:讨论模板的匹配规则。其中有令人望而生畏的特化与偏特化。但是,请相信我们在序言中所提到的:将模板作为一门语言来看待,它会变得有趣而简单。
2. 模板元编程基础
2.1 编程,元编程,模板元编程
技术的学习是一个登山的过程。第一章是最为平坦的山脚道路。而从这一章开始,则是正式的爬坡。无论是我写作还是你阅读,都需要付出比第一章更多的代价。那么问题就是,付出更多的精力学习模板是否值得?
这个问题很功利,但是一针见血。因为技术的根本目的在于解决需求。那C++的模板能做什么?
一个高(树)大(新)上(风)的回答是,C++里面的模板,犹如C中的宏、C#和Java中的自省(restropection)和反射(reflection),是一个改变语言内涵,拓展语言外延的存在。
程序最根本的目的是什么?复现真实世界或人所构想的规律,减少重复工作的成本,或通过提升规模完成人所不能及之事。但是世间之事万千,有限的程序如何重现复杂的世界呢?
答案是“抽象”。论及具体手段,无外乎“求同”与“存异”:概括一般规律,处理特殊情况。这也是软件工程所追求的目标。一般规律概括的越好,我们所付出的劳动也就越少。
同样的,作为脑力劳动的产品,程序本身也是有规律性的。《Modern C++ Design》中的前言就抛出了一连串有代表性的问题:
如何撰写更高级的C++程式?
如何应付即使在很干净的设计中仍然像雪崩一样的不相干细节?
如何构建可复用组件,使得每次在不同程式中应用组件时无需大动干戈?我们以数据结构举例。在程序里,你需要一些堆栈。这个堆栈的元素可能是整数、浮点或者别的什么类型。一份整型堆栈的代码可能是:
class StackInt
{
public:
void push(int v);
int pop();
int Find(int x)
{
for(int i = 0; i < size; ++i)
{
if(data[i] == x) { return i; }
}
}
// ... 其他代码 ...
};如果你要支持浮点了,那么你只能将代码再次拷贝出来,并作如下修改:
class StackFloat
{
public:
void push(float v);
float pop();
int Find(float x)
{
for(int i = 0; i < size; ++i)
{
if(data[i] == x) { return i; }
}
}
// ... 其他代码 ...
};当然也许你觉得这样做能充分体会代码行数增长的成就感。但是有一天,你突然发现:呀,Find 函数实现有问题了。怎么办?这个时候也许你只有两份这样的代码,那好说,一一去修正就好了。如果你有十个呢?二十个?五十个?
时间一长,你就厌倦了这样的生活。你觉得每个堆栈都差不多,但是又有点不一样。为了这一点点不一样,你付出了太多的时间。吃饭的时间,泡妞的时间,睡觉的时间,看岛国小电影顺便练习小臂力量的时间。
于是便诞生了新的技术,来消解我们的烦恼。
这个技术的名字,并不叫“模板”,而是叫“元编程”。
元(meta)无论在中文还是英文里,都是个很“抽象(abstract)”的词。因为它的本意就是“抽象”。元编程,也可以说就是“编程的抽象”。用更好理解的说法,元编程意味着你撰写一段程序A,程序A会运行后生成另外一个程序B,程序B才是真正实现功能的程序。那么这个时候程序A可以称作程序B的元程序,撰写程序A的过程,就称之为“元编程”。
回到我们的堆栈的例子。真正执行功能的,其实仍然是浮点的堆栈、整数的堆栈、各种你所需要的类型的堆栈。但是因为这些堆栈之间太相似了,仅仅有着些微的不同,我们为什么不能有一个将相似之处囊括起来,同时又能分别体现出不同之处的程序呢?很多语言都提供了这样的机会。C中的宏,C++中的模板,Python中的Duck Typing,广义上将都能够实现我们的思路。
我们的目的,是找出程序之间的相似性,进行“元编程”。而在C++中,元编程的手段,可以是宏,也可以是模板。
宏的例子姑且不论,我们来看一看模板:
template <typename T>
class Stack
{
public:
void push(T v);
T pop();
int Find(T x)
{
for(int i = 0; i < size; ++i)
{
if(data[i] == x) { return i; }
}
}
// ... 其他代码 ...
};
typedef Stack<int> StackInt;
typedef Stack<float> StackFloat;通过模板,我们可以将形形色色的堆栈代码分为两个部分,一个部分是不变的接口,以及近乎相同的实现;另外一部分是元素的类型,它们是需要变化的。因此同函数类似,需要变化的部分,由模板参数来反映;不变的部分,则是模板内的代码。可以看到,使用模板的代码,要比不使用模板的代码简洁许多。
如果元编程中所有变化的量(或者说元编程的参数),都是类型,那么这样的编程,我们有个特定的称呼,叫“泛型”。
但是你会问,模板的发明,仅仅是为了做和宏几乎一样的替换工作吗?可以说是,也可以说不是。一方面,很多时候模板就是为了替换类型,这个时候作用上其实和宏没什么区别。只是宏是基于文本的替换,被替换的文本本身没有任何语义。只有替换完成,编译器才能进行接下来的处理。而模板会在分析模板时以及实例化模板时时候都会进行检查,而且源代码中也能与调试符号一一对应,所以无论是编译时还是运行时,排错都相对简单。
但是模板和宏也有很大的不同,否则此文也就不能成立了。模板最大的不同在于它是“可以运算”的。我们来举一个例子,不过可能有点牵强。考虑我们要写一个向量逐分量乘法。只不过这个向量,它非常的大。所以为了保证速度,我们需要使用SIMD指令进行加速。假设我们有以下指令可以使用:
Int8,16: N/A
Int32 : VInt32Mul(int32x4, int32x4)
Int64 : VInt64Mul(int64x4, int64x4)
Float : VInt64Mul(floatx2, floatx2)所以对于Int8和Int16,我们需要提升到Int32,而Int32和Int64,各自使用自己的指令。所以我们需要实现下的逻辑:
for(v4a, v4b : vectorsA, vectorsB)
{
if type is Int8, Int16
VInt32Mul( ConvertToInt32(v4a), ConvertToInt32(v4b) )
elif type is Int32
VInt32Mul( v4a, v4b )
elif type is Float
...
}这里的问题就在于,如何根据 type 分别提供我们需要的实现?这里有两个难点。首先, if(type == xxx) {} 是不存在于C++中的。第二,即便存在根据 type 的分配方法,我们也不希望它在运行时branch,这样会变得很慢。我们希望它能按照类型直接就把代码编译好,就跟直接写的一样。
嗯,聪明你果然想到了,重载也可以解决这个问题。
GenericMul(int8x4, int8x4);
GenericMul(int16x4, int16x4);
GenericMul(int32x4, int32x4);
GenericMul(int64x4, int64x4);
// 其它 Generic Mul ...
for(v4a, v4b : vectorsA, vectorsB)
{
GenericMul(v4a, v4b);
}
这样不就可以了吗?
唔,你赢了,是这样没错。但是问题是,我这个平台是你可没见过,它叫 Deep Thought, 特别缺心眼儿,不光有 int8,还有更奇怪的 int9, int11,以及可以代表世间万物的 int42。你总不能为之提供所有的重载吧?这简直就像你枚举了所有程序的输入,并为之提供了对应的输出一样。
好吧,我承认这个例子还是太牵强了。不过相信我,在你阅读完第二章和第三章之后,你会将这些特性自如地运用到你的程序之中。你的程序将会变成体现模板“可运算”威力的最好例子。
2.2 模板世界的If-Then-Else:类模板的特化与偏特化
2.2.1 根据类型执行代码
前一节的示例提出了一个要求:需要做出根据类型执行不同代码。要达成这一目的,模板并不是唯一的途径。比如之前我们所说的重载。如果把眼界放宽一些,虚函数也是根据类型执行代码的例子。此外,在C语言时代,也会有一些技法来达到这个目的,比如下面这个例子,我们需要对两个浮点做加法, 或者对两个整数做乘法:
struct Variant
{
union
{
int x;
float y;
} data;
uint32 typeId;
};
Variant addFloatOrMulInt(Variant const* a, Variant const* b)
{
Variant ret;
assert(a->typeId == b->typeId);
if (a->typeId == TYPE_INT)
{
ret.x = a->x * b->x;
}
else
{
ret.y = a->y + b->y;
}
return ret;
}
更常见的是 void*:
#define BIN_OP(type, a, op, b, result) (*(type *)(result)) = (*(type const *)(a)) op (*(type const*)(b))
void doDiv(void* out, void const* data0, void const* data1, DATA_TYPE type)
{
if(type == TYPE_INT)
{
BIN_OP(int, data0, *, data1, out);
}
else
{
BIN_OP(float, data0, +, data1, out);
}
}在C++中比如在 Boost.Any 的实现中,运用了 typeid 来查询类型信息。和 typeid 同属于RTTI机制的 dynamic_cast,也经常会用来做类型判别的工作。我想你应该写过类似于下面的代码:
IAnimal* animal = GetAnimalFromSystem();
IDog* maybeDog = dynamic_cast<IDog*>(animal);
if(maybeDog)
{
maybeDog->Wangwang();
}
ICat* maybeCat = dynamic_cast<ICat*>(animal);
if(maybeCat)
{
maybeCat->Moemoe();
}当然,在实际的工作中,我们建议把需要 dynamic_cast 后执行的代码,尽量变成虚函数。不过这个已经是另外一个问题了。我们看到,不管是哪种方法都很难避免 if 的存在。而且因为输入数据的类型是模糊的,经常需要强制地、没有任何检查的转换成某个类型,因此很容易出错。
但是模板与这些方法最大的区别并不在这里。模板无论其参数或者是类型,它都是一个编译期分派的办法。编译期就能确定的东西既可以做类型检查,编译器也能进行优化,砍掉任何不必要的代码执行路径。例如在上例中,
template <typename T> T addFloatOrMulInt(T a, T b);
// 迷之代码1:用于T是float的情况
// 迷之代码2:用于T是int时的情况如果你运用了模板来实现,那么当传入两个不同类型的变量,或者不是 int 和 float 变量,编译器就会提示错误。但是如果使用了我们前述的 Variant 来实现,编译器可就管不了那么多了。但是,成也编译期,败也编译期。最严重的“缺点”,就是你没办法根据用户输入或者别的什么在运行期间可能发生变化的量来决定它产生、或执行什么代码。比如下面的代码段,它是不成立的。
template <int i, int j>
int foo() { return i + j; }
int main()
{
cin >> x >> y;
return foo<x, y>();
}这点限制也粉碎了妄图用模板来包办工厂(Factory)甚至是反射的梦想。尽管在《Modern C++ Design》中(别问我为什么老举这本书,因为《C++ Templates》和《Generic Programming》我只是囫囵吞枣读过,基本不记得了)大量运用模板来简化工厂方法;同时C++11/14中的一些机制如Variadic Template更是让这一问题的解决更加彻底。但无论如何,直到C++11/14,光靠模板你就是写不出依靠类名或者ID变量产生类型实例的代码。
所以说,从能力上来看,模板能做的事情都是编译期完成的。编译期完成的意思就是,当你编译一个程序的时候,所有的量就都已经确定了。比如下面的这个例子:
int a = 3, b = 5;
Variant aVar, bVar;
aVar.setInt(a); // 我们新加上的方法,怎么实现的无所谓,大家明白意思就行了。
bVar.setInt(b);
Variant result = addFloatOrMulInt(aVar, bVar);除非世界末日,否则这个例子里不管你怎么蹦跶,单看代码我们就能知道, aVar 和 bVar 都一定会是整数。所以如果有合适的机制,编译器就能知道此处的 addFloatOrMulInt 中只需要执行 Int 路径上的代码,而且编译器在此处也能单独为 Int 路径生成代码,从而去掉那个不必要的 if。
在模板代码中,这个“合适的机制”就是指“特化”和“部分特化(Partial Specialization)”,后者也叫“偏特化”。
2.2.2 特化
我的高中物理老师对我说过一句令我受用至今的话:把自己能做的事情做好。编写模板程序也是一样。当你试图用模板解决问题之前,先撇开那些复杂的语法要素,用最直观的方式表达你的需求:
// 这里是伪代码,意思一下
int|float addFloatOrMulInt(a, b)
{
if(type is Int)
{
return a * b;
}
else if (type is Float)
{
return a + b;
}
}
void foo()
{
float a, b, c;
c = addFloatOrMulInt(a, b); // c = a + b;
int x, y, z;
z = addFloatOrMulInt(x, y); // z = x * y;
}因为这一节是讲类模板有关的特化和偏特化机制,所以我们不用普通的函数,而是用类的静态成员函数来做这个事情(这就是典型的没事找抽型):
// 这里仍然是伪代码,意思一下,too。
class AddFloatOrMulInt
{
static int|float Do(a, b)
{
if(type is Int)
{
return a * b;
}
else if (type is Float)
{
return a + b;
}
}
};
void foo()
{
float a, b, c;
c = AddFloatOrMulInt::Do(a, b); // c = a + b;
int x, y, z;
z = AddFloatOrMulInt::Do(x, y); // z = x * y;
}好,意思表达清楚了。我们先从调用方的角度,把这个形式改写一下:
void foo()
{
float a, b, c;
c = AddFloatOrMulInt<float>::Do(a, b); // c = a + b;
int x, y, z;
z = AddFloatOrMulInt<int>::Do(x, y); // z = x * y;
}也许你不明白为什么要改写成现在这个样子。看不懂不怪你,怪我讲得不好。但是你别急,先看看这样改写以后能不能跟我们的目标接近一点。如果我们把 AddFloatOrMulInt<float>::Do 看作一个普通的函数,那么我们可以写两个实现出来:
float AddFloatOrMulInt<float>::Do(float a, float b)
{
return a + b;
}
int AddFloatOrMulInt<int>::Do(int a, int b)
{
return a * b;
}
void foo()
{
float a, b, c;
c = AddFloatOrMulInt<float>::Do(a, b); // c = a + b;
int x, y, z;
z = AddFloatOrMulInt<int>::Do(x, y); // z = x * y;
}这样是不是就很开心了?我们更进一步,把 AddFloatOrMulInt<int>::Do 换成合法的类模板:
// 这个是给float用的。
template <typename T> class AddFloatOrMulInt
{
T Do(T a, T b)
{
return a + b;
}
};
// 这个是给int用的。
template <typename T> class AddFloatOrMulInt
{
T Do(T a, T b)
{
return a * b;
}
};
void foo()
{
float a, b, c;
// 嗯,我们需要 c = a + b;
c = AddFloatOrMulInt<float>::Do(a, b);
// ... 觉得哪里不对劲 ...
// ...
// ...
// ...
// 啊!有两个AddFloatOrMulInt,class看起来一模一样,要怎么区分呢!
}好吧,问题来了!如何要让两个内容不同,但是模板参数形式相同的类进行区分呢?特化!特化(specialization)是根据一个或多个特殊的整数或类型,给出模板实例化时的一个指定内容。我们先来看特化是怎么应用到这个问题上的。
// 首先,要写出模板的一般形式(原型)
template <typename T> class AddFloatOrMulInt
{
static T Do(T a, T b)
{
// 在这个例子里面一般形式里面是什么内容不重要,因为用不上
// 这里就随便给个0吧。
return T(0);
}
};
// 其次,我们要指定T是int时候的代码,这就是特化:
template <> class AddFloatOrMulInt<int>
{
public:
static int Do(int a, int b) //
{
return a * b;
}
};
// 再次,我们要指定T是float时候的代码:
template <> class AddFloatOrMulInt<float>
{
public:
static float Do(float a, float b)
{
return a + b;
}
};
void foo()
{
// 这里面就不写了
}我们再把特化的形式拿出来一瞧:这货有点怪啊: template <> class AddFloatOrMulInt<int>。别急,我给你解释一下。
// 我们这个模板的基本形式是什么?
template <typename T> class AddFloatOrMulInt;
// 但是这个类,是给T是Int的时候用的,于是我们写作
class AddFloatOrMulInt<int>;
// 当然,这里编译是通不过的。
// 但是它又不是个普通类,而是类模板的一个特化(特例)。
// 所以前面要加模板关键字template,
// 以及模板参数列表
template </* 这里要填什么? */> class AddFloatOrMulInt<int>;
// 最后,模板参数列表里面填什么?因为原型的T已经被int取代了。所以这里就不能也不需要放任何额外的参数了。
// 所以这里放空。
template <> class AddFloatOrMulInt<int>
{
// ... 针对Int的实现 ...
};
// Bingo!哈,这样就好了。我们来做一个练习。我们有一些类型,然后你要用模板做一个对照表,让类型对应上一个数字。我先来做一个示范:
template <typename T> class TypeToID
{
public:
static int const ID = -1;
};
template <> class TypeToID<uint8_t>
{
public:
static int const ID = 0;
};然后呢,你的任务就是,要所有无符号的整数类型的特化(其实就是uint8_t到uint64_t啦),把所有的基本类型都赋予一个ID(当然是不一样的啦)。当你做完后呢,可以把类型所对应的ID打印出来,我仍然以 uint8_t 为例:
void PrintID()
{
cout << "ID of uint8_t: " << TypeToID<uint8_t>::ID << endl;
}嗯,看起来挺简单的,是吧。但是这里透露出了一个非常重要的信号,我希望你已经能察觉出来了: TypeToID 如同是一个函数。这个函数只能在编译期间执行。它输入一个类型,输出一个ID。
如果你体味到了这一点,那么恭喜你,你的模板元编程已经开悟了。
2.2.3 特化:一些其它问题
在上一节结束之后,你一定做了许多的练习。我们再来做三个练习。第一,给float一个ID;第二,给void*一个ID;第三,给任意类型的指针一个ID。先来做第一个:
// ...
// TypeToID 的模板“原型”
// ...
template <> class TypeToID<float>
{
static int const ID = 0xF10A7;
};嗯, 这个你已经了然于心了。那么void*呢?你想了想,这已经是一个复合类型了。不错你还是战战兢兢地写了下来:
template <> class TypeToID<void*>
{
static int const ID = 0x401d;
};
void PrintID()
{
cout << "ID of uint8_t: " << TypeToID<void*>::ID << endl;
}遍译运行一下,对了。模板不过如此嘛。然后你觉得自己已经完全掌握了,并试图将所有C++类型都放到模板里面,开始了自我折磨的过程:
class ClassB {};
template <> class TypeToID<void ()>; // 函数的TypeID
template <> class TypeToID<int[3]>; // 数组的TypeID
template <> class TypeToID<int (int[3])>; // 这是以数组为参数的函数的TypeID
template <> class TypeToID<int (ClassB::*[3])(void*, float[2])>; // 我也不知道这是什么了,自己看着办吧。甚至连 const 和 volatile 都能装进去:
template <> class TypeToID<int const * volatile * const volatile>;此时就很明白了,只要 <> 内填进去的是一个C++能解析的合法类型,模板都能让你特化。不过这个时候如果你一点都没有写错的话, PrintID 中只打印了我们提供了特化的类型的ID。那如果我们没有为之提供特化的类型呢?比如说double?OK,实践出真知,我们来尝试着运行一下:
void PrintID()
{
cout << "ID of double: " << TypeToID<double>::ID << endl;
}嗯,它输出的是-1。我们顺藤摸瓜会看到, TypeToID的类模板“原型”的ID是值就是-1。通过这个例子可以知道,当模板实例化时提供的模板参数不能匹配到任何的特化形式的时候,它就会去匹配类模板的“原型”形式。
不过这里有一个问题要理清一下。和继承不同,类模板的“原型”和它的特化类在实现上是没有关系的,并不是在类模板中写了 ID 这个Member,那所有的特化就必须要加入 ID 这个Member,或者特化就自动有了这个成员。完全没这回事。我们把类模板改成以下形式,或许能看的更清楚一点:
template <typename T> class TypeToID
{
public:
static int const NotID = -2;
};
template <> class TypeToID<float>
{
public:
static int const ID = 1;
};
void PrintID()
{
cout << "ID of float: " << TypeToID<float>::ID << endl; // Print "1"
cout << "NotID of float: " << TypeToID<float>::NotID << endl; // Error! TypeToID<float>使用的特化的类,这个类的实现没有NotID这个成员。
cout << "ID of double: " << TypeToID<double>::ID << endl; // Error! TypeToID<double>是由模板类实例化出来的,它只有NotID,没有ID这个成员。
}这样就明白了。类模板和类模板的特化的作用,仅仅是指导编译器选择哪个编译,但是特化之间、特化和它原型的类模板之间,是分别独立实现的。所以如果多个特化、或者特化和对应的类模板有着类似的内容,很不好意思,你得写上若干遍了。
第三个问题,是写一个模板匹配任意类型的指针。对于C语言来说,因为没有泛型的概念,因此它提供了无类型的指针void*。它的优点是,所有指针都能转换成它。它的缺点是,一旦转换称它后,你就再也不知道这个指针到底是指向float或者是int或者是struct了。
比如说copy。
void copy(void* dst, void const* src, size_t elemSize, size_t elemCount, void (*copyElem)(void* dstElem, void const* srcElem))
{
void const* reader = src;
void const* writer = dst;
for(size_t i = 0; i < elemCount; ++i)
{
copyElem(writer, reader);
advancePointer(reader, elemSize); // 把Reader指针往后移动一些字节
advancePointer(writer, elemSize);
}
}为什么要提供copyElem,是因为可能有些struct需要深拷贝,所以得用特殊的copy函数。这个在C++98/03里面就体现为拷贝构造和赋值函数。
但是不管怎么搞,因为这个函数的参数只是void*而已,当你使用了错误的elemSize,或者传入了错误的copyElem,就必须要到运行的时候才有可能看出来。注意,这还只是有可能而已。
那么C++有了模板后,能否既能匹配任意类型的指针,同时又保留了类型信息呢?答案是显然的。至于怎么写,那就得充分发挥你的直觉了:
首先,我们需要一个typename T来指代“任意类型”这四个字:
template <typename T>接下来,我们要写函数原型:
void copy(?? dest, ?? src, size_t elemCount);这里的 ?? 要怎么写呢?既然我们有了模板类型参数T,那我们不如就按照经验,写 T* 看看。
template <typename T>
void copy(T* dst, T const* src, size_t elemCount);编译一下,咦,居然通过了。看来这里的语法与我们以前学到的知识并没有什么不同。这也是语言设计最重要的一点原则:一致性。它可以让你辛辛苦苦体验到的规律不至于白费。
最后就是实现:
template <typename T>
void copy(T* dst, T const* src, size_t elemCount)
{
for(size_t i = 0; i < elemCount; ++i)
{
dst[i] = src[i];
}
}是不是简洁了许多?你不需要再传入size;只要你有正确的赋值函数,也不需要提供定制的copy;也不用担心dst和src的类型不匹配了。
最后,我们把函数模板学到的东西,也应用到类模板里面:
template <typename T> // 嗯,需要一个T
class TypeToID<T*> // 我要对所有的指针类型特化,所以这里就写T*
{
public:
static int const ID = 0x80000000; // 用最高位表示它是一个指针
};最后写个例子来测试一下,看看我们的 T* 能不能搞定 float*:
void PrintID()
{
cout << "ID of float*: " << TypeToID<float*>::ID << endl;
}哈哈,大功告成。嗯,别急着高兴。待我问一个问题:你知道 TypeToID<float*> 后,这里的T是什么吗?换句话说,你知道下面这段代码打印的是什么吗?
// ...
// TypeToID 的其他代码,略过不表
// ...
template <typename T> // 嗯,需要一个T
class TypeToID<T*> // 我要对所有的指针类型特化,所以这里就写T*
{
public:
typedef T SameAsT;
static int const ID = 0x80000000; // 用最高位表示它是一个指针
};
void PrintID()
{
cout << "ID of float*: " << TypeToID< TypeToID<float*>::SameAsT >::ID << endl;
}别急着运行,你先猜。
------------------------- 这里是给勤于思考的码猴的分割线 -------------------------------
OK,猜出来了吗,T是float。为什么呢?因为你用 float * 匹配了 T *,所以 T 就对应 float 了。没想清楚的自己再多体会一下。
嗯,所以实际上,我们可以利用这个特性做一件事情:把指针类型的那个指针给“干掉”:
template <typename T>
class RemovePointer
{
public:
typedef T Result; // 如果放进来的不是一个指针,那么它就是我们要的结果。
};
template <typename T>
class RemovePointer<T*> // 祖传牛皮藓,专治各类指针
{
public:
typedef T Result; // 正如我们刚刚讲的,去掉一层指针,把 T* 这里的 T 取出来。
};
void Foo()
{
RemovePointer<float*>::Result x = 5.0f; // 喏,用RemovePointer后,那个Result就是把float*的指针处理掉以后的结果:float啦。
std::cout << x << std::endl;
}当然啦,这里我们实现的不算是真正的 RemovePointer,因为我们只去掉了一层指针。而如果传进来的是类似 RemovePointer<int**> 这样的东西呢?是的没错,去掉一层之后还是一个指针。RemovePointer<int**>::Result 应该是一个 int*,要怎么才能实现我们想要的呢?聪明的你一定能想到:只要像剥洋葱一样,一层一层一层地剥开,不就好了吗!相应地我们应该怎么实现呢?可以把 RemovePointer 的特化版本改成这样(当然如果有一些不明白的地方你可以暂时跳过,接着往下看,很快就会明白的):
template <typename T>
class RemovePointer<T*>
{
public:
// 如果是传进来的是一个指针,我们就剥夺一层,直到指针形式不存在为止。
// 例如 RemovePointer<int**>,Result 是 RemovePointer<int*>::Result,
// 而 RemovePointer<int*>::Result 又是 int,最终就变成了我们想要的 int,其它也是类似。
typedef typename RemovePointer<T>::Result Result;
};是的没错,这便是我们想要的 RemovePointer 的样子。类似的你还可以试着实现 RemoveConst, AddPointer 之类的东西。
OK,回到我们之前的话题,如果这个时候,我需要给 int* 提供一个更加特殊的特化,那么我还得多提供一个:
// ...
// TypeToID 的其他代码,略过不表
// ...
template <typename T> // 嗯,需要一个T
class TypeToID<T*> // 我要对所有的指针类型特化,所以这里就写T*
{
public:
typedef T SameAsT;
static int const ID = 0x80000000; // 用最高位表示它是一个指针
};
template <> // 嗯,int* 已经是个具体的不能再具体的类型了,所以模板不需要额外的类型参数了
class TypeToID<int*> // 嗯,对int*的特化。在这里呢,要把int*整体看作一个类型
{
public:
static int const ID = 0x12345678; // 给一个缺心眼的ID
};
void PrintID()
{
cout << "ID of int*: " << TypeToID<int*>::ID << endl;
}嗯,这个时候它会输出0x12345678的十进制(大概?)。
可能会有较真的人说,int* 去匹配 T 或者 T*,也是合法的。就和你说22岁以上能结婚,那24岁当然也能结婚一样。
那为什么 int* 就会找 int*,float *因为没有合适的特化就去找 T*,更一般的就去找 T 呢?废话,有专门为你准备的东西你不用,非要自己找事?这就是直觉。
但是呢,直觉对付更加复杂的问题还是没用的(也不是没用,主要是你没这个直觉了)。我们要把这个直觉,转换成合理的规则——即模板的匹配规则。
当然,这个匹配规则是对复杂问题用的,所以我们会到实在一眼看不出来的时候才会动用它。一开始我们只要把握:模板是从最特殊到最一般形式进行匹配的 就可以了。
2.3 即用即推导
2.3.1 视若无睹的语法错误
这一节我们将讲述模板一个非常重要的行为特点:那就是什么时候编译器会对模板进行推导,推导到什么程度。
这一知识,对于理解模板的编译期行为、以及修正模板编译错误都非常重要。
我们先来看一个例子:
template <typename T> struct X {};
template <typename T> struct Y
{
typedef X<T> ReboundType; // 类型定义1
typedef typename X<T>::MemberType MemberType; // 类型定义2
typedef UnknownType MemberType3; // 类型定义3
void foo()
{
X<T> instance0;
typename X<T>::MemberType instance1;
WTF instance2
大王叫我来巡山 - + &
}
};把这段代码编译一下,类型定义3出错,其它的都没问题。不过到这里你应该会有几个问题:
- 不是
struct X<T>的定义是空的吗?为什么在struct Y内的类型定义2使用了X<T>::MemberType编译器没有报错? - 类型定义2中的
typename是什么鬼?为什么类型定义1就不需要? - 为什么类型定义3会导致编译错误?
- 为什么
void foo()在MSVC下什么错误都没报?
这时我们就需要请出C++11标准 —— 中的某些概念了。这是我们到目前为止第一次参阅标准。我希望能尽量减少直接参阅标准的次数,因此即便是极为复杂的模板匹配决议我都暂时没有引入标准中的描述。
然而,Template引入的“双阶段名称查找(Two phase name lookup)”堪称是C++中最黑暗的角落 —— 这是LLVM的团队自己在博客上说的 —— 因此在这里,我们还是有必要去了解标准中是如何规定的。
2.3.2 名称查找:I am who I am
在C++标准中对于“名称查找(name lookup)”这个高大上的名词的诠释,主要集中出现在三处。第一处是3.4节,标题名就叫“Name Lookup”;第二处在10.2节,继承关系中的名称查找;第三处在14.6节,名称解析(name resolution)。
名称查找/名称解析,是编译器的基石。对编译原理稍有了解的人,都知道“符号表”的存在及重要意义。考虑一段最基本的C代码:
int a = 0;
int b;
b = (a + 1) * 2;
printf("Result: %d", b);在这段代码中,所有出现的符号可以分为以下几类:
int:类型标识符,代表整型;a,b,printf:变量名或函数名;=,+,*:运算符;,,;,(,):分隔符;
那么,编译器怎么知道int就是整数类型,b=(a+1)*2中的a和b就是整型变量呢?这就是名称查找/名称解析的作用:它告诉编译器,这个标识符(identifer)是在哪里被声明或定义的,它究竟是什么意思。
也正因为这个机制非常基础,所以它才会面临各种可能的情况,编译器也要想尽办法让它在大部分场合都表现的合理。比如我们常见的作用域规则,就是为了对付名称在不同代码块中传播、并且遇到重名要如何处理的问题。下面是一个最简单的、大家在语言入门过程中都会碰到的一个例子:
int a = 0;
void f() {
int a = 0;
a += 2;
printf("Inside <a>: %d\n", a);
}
void g() {
printf("Outside <a>: %d\n", a);
}
int main() {
f();
g();
}
/* ------------ Console Output -----------------
Inside <a>: 2
Outside <a>: 0
--------------- Console Output -------------- */我想大家尽管不能处理所有名称查找中所遇到的问题,但是对一些常见的名称查找规则也有了充分的经验,可以解决一些常见的问题。
但是模板的引入,使得名称查找这一本来就不简单的基本问题变得更加复杂了。
考虑下面这个例子:
struct A { int a; };
struct AB { int a, b; };
struct C { int c; };
template <typename T> foo(T& v0, C& v1){
v0.a = 1;
v1.a = 2;
v1.c = 3;
}简单分析上述代码很容易得到以下结论:
- 函数
foo中的变量v1已经确定是struct C的实例,所以,v1.a = 2;会导致编译错误,v1.c = 3;是正确的代码; - 对于变量
v0来说,这个问题就变得很微妙。如果v0是struct A或者struct AB的实例,那么foo中的语句v0.a = 1;就是正确的。如果是struct C,那么这段代码就是错误的。
因此在模板定义的地方进行语义分析,并不能完全得出代码是正确或者错误的结论,只有到了实例化阶段,确定了模板参数的类型后,才知道这段代码正确与否。令人高兴的是,在这一问题上,我们和C++标准委员会的见地一致,说明我们的C++水平已经和Herb Sutter不分伯仲了。既然我们和Herb Sutter水平差不多,那凭什么人家就吃香喝辣?下面我们来选几条标准看看服不服:
14.6 名称解析(Name resolution)
1) 模板定义中能够出现以下三类名称:
- 模板名称、或模板实现中所定义的名称;
- 和模板参数有关的名称;
- 模板定义所在的定义域内能看到的名称。
…
9) … 如果名字查找和模板参数有关,那么查找会延期到模板参数全都确定的时候。 …
10) 如果(模板定义内出现的)名字和模板参数无关,那么在模板定义处,就应该找得到这个名字的声明。…
14.6.2 依赖性名称(Dependent names)
1) …(模板定义中的)表达式和类型可能会依赖于模板参数,并且模板参数会影响到名称查找的作用域 … 如果表达式中有操作数依赖于模板参数,那么整个表达式都依赖于模板参数,名称查找延期到模板实例化时进行。并且定义时和实例化时的上下文都会参与名称查找。(依赖性)表达式可以分为类型依赖(类型指模板参数的类型)或值依赖。
14.6.2.2 类型依赖的表达式
2) 如果成员函数所属的类型是和模板参数有关的,那么这个成员函数中的
this就认为是类型依赖的。14.6.3 非依赖性名称(Non-dependent names)
1) 非依赖性名称在模板定义时使用通常的名称查找规则进行名称查找。
Working Draft: Standard of Programming Language C++, N3337
知道差距在哪了吗:人家会说黑话。什么时候咱们也会说黑话了,就是标准委员会成员了,反正懂得也不比他们少。不过黑话确实不太好懂 —— 怪我翻译不好的人,自己看原文,再说好懂了人家还靠什么吃饭 —— 我们来举一个例子:
int a;
struct B { int v; }
template <typename T> struct X {
B b; // B 是第三类名字,b 是第一类
T t; // T 是第二类
X* anthor; // X 这里代指 X<T>,第一类
typedef int Y; // int 是第三类
Y y; // Y 是第一类
C c; // C 什么都不是,编译错误。
void foo() {
b.v += y; // b 是第一类,非依赖性名称
b.v *= T::s_mem; // T::s_mem 是第二类
// s_mem的作用域由T决定
// 依赖性名称,类型依赖
}
};所以,按照标准的意思,名称查找会在模板定义和实例化时各做一次,分别处理非依赖性名称和依赖性名称的查找。这就是“两阶段名称查找”这一名词的由来。只不过这个术语我也不知道是谁发明的,它并没有出现的标准上,但是频繁出现在StackOverflow和Blog上。
接下来,我们就来解决2.3.1节中留下的几个问题。
先看第四个问题。为什么MSVC中,模板函数的定义内不管填什么编译器都不报错?因为MSVC在分析模板中成员函数定义时没有做任何事情。至于为啥连“大王叫我来巡山”都能过得去,这是C++语法/语义分析的特殊性导致的。
C++是个非常复杂的语言,以至于它的编译器,不可能通过词法-语法-语义多趟分析清晰分割,因为它的语义将会直接干扰到语法:
void foo(){
A<T> b;
}在这段简短的代码中,就包含了两个歧义的可能,一是A是模板,于是A<T>是一个实例化的类型,b是变量,另外一种是比较表达式(Comparison Expression)的组合,((A < T) > b)。
甚至词法分析也会受到语义的干扰,C++11中才明确被修正的vector<vector<int>>,就因为>>被误解为右移或流操作符,而导致某些编译器上的错误。因此,在语义没有确定之前,连语法都没有分析的价值。
大约是基于如此考量,为了偷懒,MSVC将包括所有模板成员函数的语法/语义分析工作都挪到了第二个Phase,于是乎连带着语法分析都送进了第二个阶段。符合标准么?显然不符合。
但是这里值得一提的是,MSVC的做法和标准相比,虽然投机取巧,但并非有弊无利。我们来先说一说坏处。考虑以下例子:
// ----------- X.h ------------
template <typename T> struct X {
// 实现代码
};
// ---------- X.cpp -----------
// ... 一些代码 ...
X<int> xi;
// ... 一些代码 ...
X<float> xf;
// ... 一些代码 ...此时如果X中有一些与模板参数无关的错误,如果名称查找/语义分析在两个阶段完成,那么这些错误会很早、且唯一的被提示出来;但是如果一切都在实例化时处理,那么可能会导致不同的实例化过程提示同样的错误。而模板在运用过程中,往往会产生很多实例,此时便会大量报告同样的错误。
当然,MSVC并不会真的这么做。根据推测,最终他们是合并了相同的错误。因为即便对于模板参数相关的编译错误,也只能看到最后一次实例化的错误信息:
template <typename T> struct X {};
template <typename T> struct Y
{
typedef X<T> ReboundType; // 类型定义1
void foo()
{
X<T> instance0;
X<T>::MemberType instance1;
WTF instance2
}
};
void poo(){
Y<int>::foo();
Y<float>::foo();
}MSVC下和模板相关的错误只有一个:
error C2039: 'MemberType': is not a member of 'X<T>'
with
[
T=float
]然后是一些语法错误,比如MemberType不是一个合法的标识符之类的。这样甚至你会误以为int情况下模板的实例化是正确的。虽然在有了经验之后会发现这个问题挺荒唐的,但是仍然会让新手有困惑。
相比之下,更加遵守标准的Clang在错误提示上就要清晰许多:
error: unknown type name 'WTF'
WTF instance2
^
error: expected ';' at end of declaration
WTF instance2
^
;
error: no type named 'MemberType' in 'X<int>'
typename X<T>::MemberType instance1;
~~~~~~~~~~~~~~~^~~~~~~~~~
note: in instantiation of member function 'Y<int>::foo' requested here
Y<int>::foo();
^
error: no type named 'MemberType' in 'X<float>'
typename X<T>::MemberType instance1;
~~~~~~~~~~~~~~~^~~~~~~~~~
note: in instantiation of member function 'Y<float>::foo' requested here
Y<float>::foo();
^
4 errors generated.可以看到,Clang的提示和标准更加契合。它很好地区分了模板在定义和实例化时分别产生的错误。
另一个缺点也与之类似。因为没有足够的检查,如果你写的模板没有被实例化,那么很可能缺陷会一直存在于代码之中。特别是模板代码多在头文件。虽然不如接口那么重要,但也是属于被公开的部分,别人很可能会踩到坑上。缺陷一旦传播开修复起来就没那么容易了。
但是正如我前面所述,这个违背了标准的特性,并不是一无是处。首先,它可以完美的兼容标准。符合标准的、能够被正确编译的代码,一定能够被MSVC的方案所兼容。其次,它带来了一个非常有趣的特性,看下面这个例子:
struct A;
template <typename T> struct X {
int v;
void convertTo(A& a) {
a.v = v; // 这里需要A的实现
}
};
struct A { int v; };
void main() {
X<int> x;
x.foo(5);
}这个例子在Clang中是错误的,因为:
error: variable has incomplete type 'A'
A a;
^
note: forward declaration of 'A'
struct A;
^
1 error generated.符合标准的写法需要将模板类的定义,和模板函数的定义分离开:
TODO 此处例子不够恰当,并且描述有歧义。需要在未来版本中修订。
struct A;
template <typename T> struct X {
int v;
void convertTo(A& a);
};
struct A { int v; };
template <typename T> void X<T>::convertTo(A& a) {
a.v = v;
}
void main() {
X<int> x;
x.foo(5);
}但是其实我们知道,foo要到实例化之后,才需要真正的做语义分析。在MSVC上,因为函数实现就是到模板实例化时才处理的,所以这个例子是完全正常工作的。因此在上面这个例子中,MSVC的实现要比标准更加易于写和维护,是不是有点写Java/C#那种声明实现都在同一处的清爽感觉了呢!
扩展阅读: The Dreaded Two-Phase Name Lookup
2.3.3 “多余的” typename 关键字
到了这里,2.3.1 中提到的四个问题,还有三个没有解决:
template <typename T> struct X {};
template <typename T> struct Y
{
typedef X<T> ReboundType; // 这里为什么是正确的?
typedef typename X<T>::MemberType MemberType2; // 这里的typename是做什么的?
typedef UnknownType MemberType3; // 这里为什么会出错?
};我们运用我们2.3.2节中学习到的标准,来对Y内部做一下分析:
template <typename T> struct Y
{
// X可以查找到原型;
// X<T>是一个依赖性名称,模板定义阶段并不管X<T>是不是正确的。
typedef X<T> ReboundType;
// X可以查找到原型;
// X<T>是一个依赖性名称,X<T>::MemberType也是一个依赖性名称;
// 所以模板声明时也不会管X模板里面有没有MemberType这回事。
typedef typename X<T>::MemberType MemberType2;
// UnknownType 不是一个依赖性名称
// 而且这个名字在当前作用域中不存在,所以直接报错。
typedef UnknownType MemberType3;
};下面,唯一的问题就是第二个:typename是做什么的?
对于用户来说,这其实是一个语法噪音。也就是说,其实就算没有它,语法上也说得过去。事实上,某些情况下MSVC的确会在标准需要的时候,不用写typename。但是标准中还是规定了形如 T::MemberType 这样的qualified id 在默认情况下不是一个类型,而是解释为T的一个成员变量MemberType,只有当typename修饰之后才能作为类型出现。
事实上,标准对typename的使用规定极为复杂,也算是整个模板中的难点之一。如果想了解所有的标准,需要阅读标准14.6节下2-7条,以及14.6.2.1第一条中对于current instantiation的解释。
简单来说,如果编译器能在出现的时候知道它是一个类型,那么就不需要typename,如果必须要到实例化的时候才能知道它是不是合法,那么定义的时候就把这个名称作为变量而不是类型。
我们用一行代码来说明这个问题:
a * b;在没有模板的情况下,这个语句有两种可能的意思:如果a是一个类型,这就是定义了一个指针b,它拥有类型a*;如果a是一个对象或引用,这就是计算一个表达式a*b,虽然结果并没有保存下来。可是如果上面的a是模板参数的成员,会发生什么呢?
template <typename T> void meow()
{
T::a * b; // 这是指针定义还是表达式语句?
}编译器对模板进行语法检查的时候,必须要知道上面那一行到底是个什么——这当然可以推迟到实例化的时候进行(比如VC,这也是上面说过VC可以不加typename的原因),不过那是另一个故事了——显然在模板定义的时候,编译器并不能妄断。因此,C++标准规定,在没有typename约束的情况下认为这里T::a不是类型,因此T::a * b; 会被当作表达式语句(例如乘法);而为了告诉编译器这是一个指针的定义,我们必须在T::a之前加上typename关键字,告诉编译器T::a是一个类型,这样整个语句才能符合指针定义的语法。
在这里,我举几个例子帮助大家理解typename的用法,这几个例子已经足以涵盖日常使用(预览):
struct A;
template <typename T> struct B;
template <typename T> struct X {
typedef X<T> _A; // 编译器当然知道 X<T> 是一个类型。
typedef X _B; // X 等价于 X<T> 的缩写
typedef T _C; // T 不是一个类型还玩毛
// !!!注意我要变形了!!!
class Y {
typedef X<T> _D; // X 的内部,既然外部高枕无忧,内部更不用说了
typedef X<T>::Y _E; // 嗯,这里也没问题,编译器知道Y就是当前的类型,
// 这里在VS2015上会有错,需要添加 typename,
// Clang 上顺利通过。
typedef typename X<T*>::Y _F; // 这个居然要加 typename!
// 因为,X<T*>和X<T>不一样哦,
// 它可能会在实例化的时候被别的偏特化给抢过去实现了。
};
typedef A _G; // 嗯,没问题,A在外面声明啦
typedef B<T> _H; // B<T>也是一个类型
typedef typename B<T>::type _I; // 嗯,因为不知道B<T>::type的信息,
// 所以需要typename
typedef B<int>::type _J; // B<int> 不依赖模板参数,
// 所以编译器直接就实例化(instantiate)了
// 但是这个时候,B并没有被实现,所以就出错了
};2.4 本章小结
这一章是写作中最艰难的一章,中间停滞了将近一年。因为要说清楚C++模板中一些语法噪音和设计决议并不是一件轻松的事情。不过通过这一章的学习,我们知道了下面这几件事情:
- 部分特化/偏特化 和 特化 相当于是模板实例化过程中的
if-then-else。这使得我们根据不同类型,选择不同实现的需求得以实现; - 在 2.3.3 一节我们插入了C++模板中最难理解的内容之一:名称查找。名称查找是语义分析的一个环节,模板内书写的 变量声明、typedef、类型名称 甚至 类模板中成员函数的实现 都要符合名称查找的规矩才不会出错;
- C++编译器对语义的分析的原则是“大胆假设,小心求证”:在能求证的地方尽量求证 —— 比如两段式名称查找的第一阶段;无法检查的地方假设你是正确的 —— 比如
typedef typename A<T>::MemberType _X;在模板定义时因为T不明确不会轻易判定这个语句的死刑。
从下一章开始,我们将进入元编程环节。我们将使用大量的示例,一方面帮助巩固大家学到的模板知识,一方面也会引导大家使用函数式思维去解决常见的问题。
3 深入理解特化与偏特化
3.1 正确的理解偏特化
3.1.1 偏特化与函数重载的比较
在前面的章节中,我们介绍了偏特化的形式、也介绍了简单的用例。因为偏特化和函数重载存在着形式上的相似性,因此初学者便会借用重载的概念,来理解偏特化的行为。只是,重载和偏特化尽管相似但仍有差异。
我们来先看一个函数重载的例子:
void doWork(int);
void doWork(float);
void doWork(int, int);
void f() {
doWork(0);
doWork(0.5f);
doWork(0, 0);
}在这个例子中,我们展现了函数重载可以在两种条件下工作:参数数量相同、类型不同;参数数量不同。
仿照重载的形式,我们通过特化机制,试图实现一个模板的“重载”:
template <typename T> struct DoWork; // (0) 这是原型
template <> struct DoWork<int> {}; // (1) 这是 int 类型的"重载"
template <> struct DoWork<float> {}; // (2) 这是 float 类型的"重载"
template <> struct DoWork<int, int> {}; // (3) 这是 int, int 类型的“重载”
void f(){
DoWork<int> i;
DoWork<float> f;
DoWork<int, int> ii;
}这个例子在字面上“看起来”并没有什么问题,可惜编译器在编译的时候仍然提示出错了goo.gl/zI42Zv:
5 : error: too many template arguments for class template 'DoWork'
template <> struct DoWork<int, int> {}; // 这是 int, int 类型的“重载”
^ ~~~~
1 : note: template is declared here
template <typename T> struct DoWork {}; // 这是原型
~~~~~~~~~~~~~~~~~~~~~ ^从编译出错的失望中冷静一下,在仔细看看函数特化/偏特化和一般模板的不同之处:
template <typename T> class X {};
template <typename T> class X <T*> {};
// ^^^^ 注意这里对,就是这个<T*>,跟在X后面的“小尾巴”,我们称作实参列表,决定了第二条语句是第一条语句的跟班。所以,第二条语句,即“偏特化”,必须要符合原型X的基本形式:那就是只有一个模板参数。这也是为什么DoWork尝试以template <> struct DoWork<int, int>的形式偏特化的时候,编译器会提示模板实参数量过多。
另外一方面,在类模板的实例化阶段,它并不会直接去寻找 template <> struct DoWork<int, int>这个小跟班,而是会先找到基本形式,template <typename T> struct DoWork;,然后再去寻找相应的特化。
我们以DoWork<int> i;为例,尝试复原一下编译器完成整个模板匹配过程的场景,帮助大家理解。看以下示例代码:
template <typename T> struct DoWork; // (0) 这是原型
template <> struct DoWork<int> {}; // (1) 这是 int 类型的特化
template <> struct DoWork<float> {}; // (2) 这是 float 类型的特化
template <typename U> struct DoWork<U*> {}; // (3) 这是指针类型的偏特化
DoWork<int> i; // (4)
DoWork<float*> pf; // (5)首先,编译器分析(0), (1), (2)三句,得知(0)是模板的原型,(1),(2),(3)是模板(0)的特化或偏特化。我们假设有两个字典,第一个字典存储了模板原型,我们称之为TemplateDict。第二个字典TemplateSpecDict,存储了模板原型所对应的特化/偏特化形式。所以编译器在处理这几句时,可以视作
// 以下为伪代码
TemplateDict[DoWork<T>] = {
DoWork<int>,
DoWork<float>,
DoWork<U*>
};然后 (4) 试图以int实例化类模板DoWork。它会在TemplateDict中,找到DoWork,它有一个形式参数T接受类型,正好和我们实例化的要求相符合。并且此时T被推导为int。(5) 中的float*也是同理。
{ // 以下为 DoWork<int> 查找对应匹配的伪代码
templateProtoInt = TemplateDict.find(DoWork, int); // 查找模板原型,查找到(0)
template = templatePrototype.match(int); // 以 int 对应 int 匹配到 (1)
}
{ // 以下为DoWork<float*> 查找对应匹配的伪代码
templateProtoIntPtr = TemplateDict.find(DoWork, float*) // 查找模板原型,查找到(0)
template = templateProtoIntPtr.match(float*) // 以 float* 对应 U* 匹配到 (3),此时U为float
}那么根据上面的步骤所展现的基本原理,我们随便来几个练习:
template <typename T, typename U> struct X ; // 0
// 原型有两个类型参数
// 所以下面的这些偏特化的实参列表
// 也需要两个类型参数对应
template <typename T> struct X<T, T > {}; // 1
template <typename T> struct X<T*, T > {}; // 2
template <typename T> struct X<T, T* > {}; // 3
template <typename U> struct X<U, int> {}; // 4
template <typename U> struct X<U*, int> {}; // 5
template <typename U, typename T> struct X<U*, T* > {}; // 6
template <typename U, typename T> struct X<U, T* > {}; // 7
template <typename T> struct X<unique_ptr<T>, shared_ptr<T>>; // 8
// 以下特化,分别对应哪个偏特化的实例?
// 此时偏特化中的T或U分别是什么类型?
X<float*, int> v0;
X<double*, int> v1;
X<double, double> v2;
X<float*, double*> v3;
X<float*, float*> v4;
X<double, float*> v5;
X<int, double*> v6;
X<int*, int> v7;
X<double*, double> v8;在上面这段例子中,有几个值得注意之处。首先,偏特化时的模板形参,和原型的模板形参没有任何关系。和原型不同,它的顺序完全不影响模式匹配的顺序,它只是偏特化模式,如<U, int>中U的声明,真正的模式,是由<U, int>体现出来的。
这也是为什么在特化的时候,当所有类型都已经确定,我们就可以抛弃全部的模板参数,写出template <> struct X<int, float>这样的形式:因为所有列表中所有参数都确定了,就不需要额外的形式参数了。
其次,作为一个模式匹配,偏特化的实参列表中展现出来的“样子”,就是它能被匹配的原因。比如,struct X<T, T>中,要求模板的两个参数必须是相同的类型。而struct X<T, T*>,则代表第二个模板类型参数必须是第一个模板类型参数的指针,比如X<float***, float****>就能匹配上。当然,除了简单的指针、const和volatile修饰符,其他的类模板也可以作为偏特化时的“模式”出现,例如示例8,它要求传入同一个类型的unique_ptr和shared_ptr。C++标准中指出下列模式都是可以被匹配的:
N3337, 14.8.2.5/8
令
T是模板类型实参或者类型列表(如 int, float, double 这样的,TT是template-template实参(参见6.2节),i是模板的非类型参数(整数、指针等),则以下形式的形参都会参与匹配:
T,cv-list T,T*,template-name <T>,T&,T&&
T [ integer-constant ]
type (T),T(),T(T)
T type ::*,type T::*,T T::*
T (type ::*)(),type (T::*)(),type (type ::*)(T),type (T::*)(T),T (type ::*)(T),T (T::*)(),T (T::*)(T)
type [i],template-name <i>,TT<T>,TT<i>,TT<>
对于某些实例化,偏特化的选择并不是唯一的。比如v4的参数是<float*, float*>,能够匹配的就有三条规则,1,6和7。很显然,6还是比7好一些,因为能多匹配一个指针。但是1和6,就很难说清楚谁更好了。一个说明了两者类型相同;另外一个则说明了两者都是指针。所以在这里,编译器也没办法决定使用那个,只好报出了编译器错误。
其他的示例可以先自己推测一下, 再去编译器上尝试一番:goo.gl/9UVzje。
3.1.2 不定长的模板参数
不过这个时候也许你还不死心。有没有一种办法能够让例子DoWork像重载一样,支持对长度不一的参数列表分别偏特化/特化呢?
答案当然是肯定的。
首先,首先我们要让模板实例化时的模板参数统一到相同形式上。逆向思维一下,虽然两个类型参数我们很难缩成一个参数,但是我们可以通过添加额外的参数,把一个扩展成两个呀。比如这样:
DoWork<int, void> i;
DoWork<float, void> f;
DoWork<int, int > ii;这时,我们就能写出统一的模板原型:
template <typename T0, typename T1> struct DoWork;继而偏特化/特化问题也解决了:
template <> struct DoWork<int, void> {}; // (1) 这是 int 类型的特化
template <> struct DoWork<float, void> {}; // (2) 这是 float 类型的特化
template <> struct DoWork<int, int> {}; // (3) 这是 int, int 类型的特化显而易见这个解决方案并不那么完美。首先,不管是偏特化还是用户实例化模板的时候,都需要多撰写好几个void,而且最长的那个参数越长,需要写的就越多;其次,如果我们的DoWork在程序维护的过程中新加入了一个参数列表更长的实例,那么最悲惨的事情就会发生 —— 原型、每一个偏特化、每一个实例化都要追加上void以凑齐新出现的实例所需要的参数数量。
所幸模板参数也有一个和函数参数相同的特性:默认实参(Default Arguments)。只需要一个例子,你们就能看明白了goo.gl/TtmcY9:
template <typename T0, typename T1 = void> struct DoWork;
template <typename T> struct DoWork<T> {};
template <> struct DoWork<int> {};
template <> struct DoWork<float> {};
template <> struct DoWork<int, int> {};
DoWork<int> i;
DoWork<float> f;
DoWork<double> d;
DoWork<int, int> ii;所有参数不足,即原型中参数T1没有指定的地方,都由T1自己的默认参数void补齐了。
但是这个方案仍然有些美中不足之处。
比如,尽管我们默认了所有无效的类型都以void结尾,所以正确的类型列表应该是类似于<int, float, char, void, void>这样的形态。但你阻止不了你的用户写出类似于<void, int, void, float, char, void, void>这样不符合约定的类型参数列表。
其次,假设这段代码中有一个函数,它的参数使用了和类模板相同的参数列表类型,如下面这段代码:
template <typename T0, typename T1 = void> struct X {
static void call(T0 const& p0, T1 const& p1); // 0
};
template <typename T0> struct X<T0> {
static void call(T0 const& p0); // 1
};
void foo(){
X<int>::call(5); // 调用函数 1
X<int, float>::call(5, 0.5f); // 调用函数 0
}那么,每加一个参数就要多写一个偏特化的形式,甚至还要重复编写一些可以共享的实现。
不过不管怎么说,以长参数加默认参数的方式支持变长参数是可行的做法,这也是C++98/03时代的唯一选择。
例如,Boost.Tuple就使用了这个方法,支持了变长的Tuple:
// Tuple 的声明,来自 boost
struct null_type;
template <
class T0 = null_type, class T1 = null_type, class T2 = null_type,
class T3 = null_type, class T4 = null_type, class T5 = null_type,
class T6 = null_type, class T7 = null_type, class T8 = null_type,
class T9 = null_type>
class tuple;
// Tuple的一些用例
tuple<int> a;
tuple<double&, const double&, const double, double*, const double*> b;
tuple<A, int(*)(char, int), B(A::*)(C&), C> c;
tuple<std::string, std::pair<A, B> > d;
tuple<A*, tuple<const A*, const B&, C>, bool, void*> e;此外,Boost.MPL也使用了这个手法将boost::mpl::vector映射到boost::mpl::vector _n_上。但是我们也看到了,这个方案的缺陷很明显:代码臃肿和潜在的正确性问题。此外,过度使用模板偏特化、大量冗余的类型参数也给编译器带来了沉重的负担。
为了缓解这些问题,在C++11中,引入了变参模板(Variadic Template)。我们来看看支持了变参模板的C++11是如何实现tuple的:
template <typename... Ts> class tuple;是不是一下子简洁了很多!这里的typename... Ts相当于一个声明,是说Ts不是一个类型,而是一个不定常的类型列表。同C语言的不定长参数一样,它通常只能放在参数列表的最后。看下面的例子:
template <typename... Ts, typename U> class X {}; // (1) error!
template <typename... Ts> class Y {}; // (2)
template <typename... Ts, typename U> class Y<U, Ts...> {}; // (3)
template <typename... Ts, typename U> class Y<Ts..., U> {}; // (4) error!为什么第(1)条语句会出错呢?(1)是模板原型,模板实例化时,要以它为基础和实例化时的类型实参相匹配。因为C++的模板是自左向右匹配的,所以不定长参数只能结尾。其他形式,无论写作Ts, U,或者是Ts, V, Us,,或者是V, Ts, Us都是不可取的。(4) 也存在同样的问题。
但是,为什么(3)中, 模板参数和(1)相同,都是typename... Ts, typename U,但是编译器却并没有报错呢?
答案在这一节的早些时候。(3)和(1)不同,它并不是模板的原型,它只是Y的一个偏特化。回顾我们在之前所提到的,偏特化时,模板参数列表并不代表匹配顺序,它们只是为偏特化的模式提供的声明,也就是说,它们的匹配顺序,只是按照<U, Ts...>来,而之前的参数只是告诉你Ts是一个类型列表,而U是一个类型,排名不分先后。
在这里,我们只提到了变长模板参数的声明,如何使用我们将在第四章讲述。
3.1.3 模板的默认实参
在上一节中,我们介绍了模板对默认实参的支持。当时我们的例子很简单,默认模板实参是一个确定的类型void或者自定义的null_type:
template <
typename T0, typename T1 = void, typename T2 = void
> class Tuple;实际上,模板的默认参数不仅仅可以是一个确定的类型,它还能是以其他类型为参数的一个类型表达式。
考虑下面的例子:我们要执行两个同类型变量的除法,它对浮点、整数和其他类型分别采取不同的措施。
对于浮点,执行内置除法;对于整数,要处理除零保护,防止引发异常;对于其他类型,执行一个叫做CustomeDiv的函数。
第一步,我们先把浮点正确的写出来:
#include <type_traits>
template <typename T> T CustomDiv(T lhs, T rhs) {
// Custom Div的实现
}
template <typename T, bool IsFloat = std::is_floating_point<T>::value> struct SafeDivide {
static T Do(T lhs, T rhs) {
return CustomDiv(lhs, rhs);
}
};
template <typename T> struct SafeDivide<T, true>{ // 偏特化A
static T Do(T lhs, T rhs){
return lhs/rhs;
}
};
template <typename T> struct SafeDivide<T, false>{ // 偏特化B
static T Do(T lhs, T rhs){
return lhs;
}
};
void foo(){
SafeDivide<float>::Do(1.0f, 2.0f); // 调用偏特化A
SafeDivide<int>::Do(1, 2); // 调用偏特化B
}在实例化的时候,尽管我们只为SafeDivide指定了参数T,但是它的另一个参数IsFloat在缺省的情况下,可以根据T,求出表达式std::is_floating_point<T>::value的值作为实参的值,带入到SafeDivide的匹配中。
嗯,这个时候我们要再把整型和其他类型纳入进来,无外乎就是加这么一个参数goo.gl/0Lqywt:
#include <complex>
#include <type_traits>
template <typename T> T CustomDiv(T lhs, T rhs) {
T v;
// Custom Div的实现
return v;
}
template <
typename T,
bool IsFloat = std::is_floating_point<T>::value,
bool IsIntegral = std::is_integral<T>::value
> struct SafeDivide {
static T Do(T lhs, T rhs) {
return CustomDiv(lhs, rhs);
}
};
template <typename T> struct SafeDivide<T, true, false>{ // 偏特化A
static T Do(T lhs, T rhs){
return lhs/rhs;
}
};
template <typename T> struct SafeDivide<T, false, true>{ // 偏特化B
static T Do(T lhs, T rhs){
return rhs == 0 ? 0 : lhs/rhs;
}
};
void foo(){
SafeDivide<float>::Do(1.0f, 2.0f); // 调用偏特化A
SafeDivide<int>::Do(1, 2); // 调用偏特化B
SafeDivide<std::complex<float>>::Do({1.f, 2.f}, {1.f, -2.f}); // 调用一般形式
}当然,这时也许你会注意到,is_integral,is_floating_point和其他类类型三者是互斥的,那能不能只使用一个条件量来进行分派呢?答案当然是可以的:goo.gl/jYp5J2:
#include <complex>
#include <type_traits>
template <typename T> T CustomDiv(T lhs, T rhs) {
T v;
// Custom Div的实现
return v;
}
template <typename T, typename Enabled = std::true_type> struct SafeDivide {
static T Do(T lhs, T rhs) {
return CustomDiv(lhs, rhs);
}
};
template <typename T> struct SafeDivide<
T, typename std::is_floating_point<T>::type>{ // 偏特化A
static T Do(T lhs, T rhs){
return lhs/rhs;
}
};
template <typename T> struct SafeDivide<
T, typename std::is_integral<T>::type>{ // 偏特化B
static T Do(T lhs, T rhs){
return rhs == 0 ? 0 : lhs/rhs;
}
};
void foo(){
SafeDivide<float>::Do(1.0f, 2.0f); // 调用偏特化A
SafeDivide<int>::Do(1, 2); // 调用偏特化B
SafeDivide<std::complex<float>>::Do({1.f, 2.f}, {1.f, -2.f});
}我们借助这个例子,帮助大家理解一下这个结构是怎么工作的:
对
SafeDivide<int>- 通过匹配类模板的泛化形式,计算默认实参,可以知道我们要匹配的模板实参是
SafeDivide<int, true_type> - 计算两个偏特化的形式的匹配:A得到
<int, false_type>,和B得到<int, true_type> - 最后偏特化B的匹配结果和模板实参一致,使用它。
- 通过匹配类模板的泛化形式,计算默认实参,可以知道我们要匹配的模板实参是
针对
SafeDivide<complex<float>>- 通过匹配类模板的泛化形式,可以知道我们要匹配的模板实参是
SafeDivide<complex<float>, true_type> - 计算两个偏特化形式的匹配:A和B均得到
SafeDivide<complex<float>, false_type> - A和B都与模板实参无法匹配,所以使用原型,调用
CustomDiv
- 通过匹配类模板的泛化形式,可以知道我们要匹配的模板实参是
3.2 后悔药:SFINAE
考虑下面这个函数模板:
template <typename T, typename U>
void foo(T t, typename U::type u) {
// ...
}到本节为止,我们所有的例子都保证了一旦咱们敲定了模板参数中 T 和 U,函数参变量 t 和 u 的类型都是成立的,比如下面这样:
struct X {
typedef float type;
};
template <typename T, typename U>
void foo(T t, typename U::type u) {
// ...
}
void callFoo() {
foo<int, X>(5, 5.0); // T == int, typename U::type == X::type == float
}那么这里有一个可能都不算是问题的问题 —— 对于下面的代码,你认为它会提示怎么样的错误:
struct X {
typedef float type;
};
struct Y {
typedef float type2;
};
template <typename T, typename U>
void foo(T t, typename U::type u) {
// ...
}
void callFoo() {
foo<int, X>(5, 5.0); // T == int, typename U::type == X::type == float
foo<int, Y>(5, 5.0); // ???
}这个时候你也许会说:啊,这个简单,Y 没有 type 这个成员自然会出错啦!嗯,这个时候咱们来看看Clang给出的结果:
error: no matching function for call to 'foo'
foo<int, Y>(5, 5.0); // ???
^~~~~~~~~~~
note: candidate template ignored: substitution failure [with T = int, U = Y]: no type named 'type' in 'Y'
void foo(T t, typename U::type u) {完整翻译过来就是,直接的出错原因是没有匹配的 foo 函数,间接原因是尝试用 [T = int, U = y] 做类型替换的时候失败了,所以这个函数模板就被忽略了。等等,不是出错,而是被忽略了?那么也就是说,只要有别的能匹配的类型兜着,编译器就无视这里的失败了?
银河火箭队的阿喵说,就是这样。不信邪的朋友可以试试下面的代码:
struct X {
typedef float type;
};
struct Y {
typedef float type2;
};
template <typename T, typename U>
void foo(T t, typename U::type u) {
// ...
}
template <typename T, typename U>
void foo(T t, typename U::type2 u) {
// ...
}
void callFoo() {
foo<int, X>(5, 5.0); // T == int, typename U::type == X::type == float
foo<int, Y>( 1, 1.0 ); // ???
}这下相信编译器真的是不关心替换失败了吧。我们管这种只要有正确的候选,就无视替换失败的做法为SFINAE。
我们不用纠结这个词的发音,它来自于 Substitution failure is not an error 的首字母缩写。这一句之乎者也般难懂的话,由之乎者 —— 啊,不,Substitution,Failure和Error三个词构成。
我们从最简单的词“Error”开始理解。Error就是一般意义上的编译错误。一旦出现编译错误,大家都知道,编译器就会中止编译,并且停止接下来的代码生成和链接等后续活动。
其次,我们再说“Failure”。很多时候光看字面意思,很多人会把 Failure 和 Error 等同起来。但是实际上Failure很多场合下只是一个中性词。比如我们看下面这个虚构的例子就知道这两者的区别了。
假设我们有一个语法分析器,其中某一个规则需要匹配一个token,它可以是标识符,字面量或者是字符串,那么我们会有下面的代码:
switch(token)
{
case IDENTIFIER:
// do something
break;
case LITERAL_NUMBER:
// do something
break;
case LITERAL_STRING:
// do something
break;
default:
throw WrongToken(token);
}假如我们当前的token是 LITERAL_STRING 的时候,那么第一步它在匹配 IDENTIFIER 时,我们可以认为它失败(failure)了,但是它在第三步就会匹配上,所以它并不是一个错误。
但是如果这个token既不是标识符、也不是数字字面量、也不是字符串字面量,而且我们的语法规定除了这三类值以外其他统统都是非法的时,我们才认为它是一个error。
大家所熟知的函数重载也是如此。比如说下面这个例子:
struct A {};
struct B: public A {};
struct C {};
void foo(A const&) {}
void foo(B const&) {}
void callFoo() {
foo( A() );
foo( B() );
foo( C() );
}那么 foo( A() ) 虽然匹配 foo(B const&) 会失败,但是它起码能匹配 foo(A const&),所以它是正确的;foo( B() ) 能同时匹配两个函数原型,但是 foo(B const&) 要更好一些,因此它选择了这个原型。而 foo( C() ); 因为两个函数都匹配失败(Failure)了,所以它找不到相应的原型,这时才会报出一个编译器错误(Error)。
所以到这里我们就明白了,在很多情况下,Failure is not an error。编译器在遇到Failure的时候,往往还需要尝试其他的可能性。
好,现在我们把最后一个词,Substitution,加入到我们的字典中。现在这句话的意思就是说,我们要把 Failure is not an error 的概念,推广到Substitution阶段。
所谓substitution,就是将函数模板中的形参,替换成实参的过程。概念很简洁但是实现却颇多细节,所以C++标准中对这一概念的解释比较拗口。它分别指出了以下几点:
- 什么时候函数模板会发生实参 替代(Substitute) 形参的行为;
- 什么样的行为被称作 Substitution;
- 什么样的行为不可以被称作 Substitution Failure —— 他们叫SFINAE error。
我们在此不再详述,有兴趣的同学可以参照这里,这是标准的一个精炼版本。这里我们简单的解释一下。
考虑我们有这么个函数签名:
template <
typename T0,
// 一大坨其他模板参数
typename U = /* 和前面T有关的一大坨 */
>
RType /* 和模板参数有关的一大坨 */
functionName (
PType0 /* PType0 是和模板参数有关的一大坨 */,
PType1 /* PType1 是和模板参数有关的一大坨 */,
// ... 其他参数
) {
// 实现,和模板参数有关的一大坨
}那么,在这个函数模板被实例化的时候,所有函数签名上的“和模板参数有关的一大坨”被推导出具体类型的过程,就是替换。一个更具体的例子来解释上面的“一大坨”:
template <
typename T,
typename U = typename vector<T>::iterator // 1
>
typename vector<T>::value_type // 1
foo(
T*, // 1
T&, // 1
typename T::internal_type, // 1
typename add_reference<T>::type, // 1
int // 这里都不需要 substitution
)
{
// 整个实现部分,都没有 substitution。这个很关键。
}所有标记为 1 的部分,都是需要替换的部分,而它们在替换过程中的失败(failure),就称之为替换失败(substitution failure)。
下面的代码是提供了一些替换成功和替换失败的示例:
struct X {
typedef int type;
};
struct Y {
typedef int type2;
};
template <typename T> void foo(typename T::type); // Foo0
template <typename T> void foo(typename T::type2); // Foo1
template <typename T> void foo(T); // Foo2
void callFoo() {
foo<X>(5); // Foo0: Succeed, Foo1: Failed, Foo2: Failed
foo<Y>(10); // Foo0: Failed, Foo1: Succeed, Foo2: Failed
foo<int>(15); // Foo0: Failed, Foo1: Failed, Foo2: Succeed
}在这个例子中,当我们指定 foo<Y> 的时候,substitution就开始工作了,而且会同时工作在三个不同的 foo 签名上。如果我们仅仅因为 Y 没有 type,匹配 Foo0 失败了,就宣布代码有错,中止编译,那显然是武断的。因为 Foo1 是可以被正确替换的,我们也希望 Foo1 成为 foo<Y> 的原型。
std/boost库中的 enable_if 是 SFINAE 最直接也是最主要的应用。所以我们通过下面 enable_if 的例子,来深入理解一下 SFINAE 在模板编程中的作用。
假设我们有两个不同类型的计数器(counter),一种是普通的整数类型,另外一种是一个复杂对象,它从接口 ICounter 继承,这个接口有一个成员叫做increase实现计数功能。现在,我们想把这两种类型的counter封装一个统一的调用:inc_counter。那么,我们直觉会简单粗暴的写出下面的代码:
struct ICounter {
virtual void increase() = 0;
virtual ~ICounter() {}
};
struct Counter: public ICounter {
void increase() override {
// Implements
}
};
template <typename T>
void inc_counter(T& counterObj) {
counterObj.increase();
}
template <typename T>
void inc_counter(T& intTypeCounter){
++intTypeCounter;
}
void doSomething() {
Counter cntObj;
uint32_t cntUI32;
// blah blah blah
inc_counter(cntObj);
inc_counter(cntUI32);
}我们非常希望它展现出预期的行为。因为其实我们是知道对于任何一个调用,两个 inc_counter 只有一个是能够编译正确的。“有且唯一”,我们理应当期望编译器能够挑出那个唯一来。
可惜编译器做不到这一点。首先,它就告诉我们,这两个签名
template <typename T> void inc_counter(T& counterObj);
template <typename T> void inc_counter(T& intTypeCounter);其实是一模一样的。我们遇到了 redefinition。
我们看看 enable_if 是怎么解决这个问题的。我们通过 enable_if 这个 T 对于不同的实例做个限定:
template <typename T> void inc_counter(
T& counterObj,
typename std::enable_if<
std::is_base_of<ICounter, T>::value
>::type* = nullptr );
template <typename T> void inc_counter(
T& counterInt,
typename std::enable_if<
std::is_integral<T>::value
>::type* = nullptr );然后我们解释一下,这个 enable_if 是怎么工作的,语法为什么这么丑:
首先,替换(substitution)只有在推断函数类型的时候,才会起作用。推断函数类型需要参数的类型,所以, typename std::enable_if<std::is_integral<T>::value>::type 这么一长串代码,就是为了让 enable_if 参与到函数类型中;
其次, is_integral<T>::value 返回一个布尔类型的编译器常数,告诉我们它是或者不是一个 integral type,enable_if<C> 的作用就是,如果这个 C 值为 True,那么 enable_if<C>::type 就会被推断成一个 void 或者是别的什么类型,让整个函数匹配后的类型变成 void inc_counter<int>(int & counterInt, void* dummy = nullptr); 如果这个值为 False ,那么 enable_if<false> 这个特化形式中,压根就没有这个 ::type,于是替换就失败了。和我们之前的例子中一样,这个函数原型就不会被产生出来。
所以我们能保证,无论对于 int 还是 counter 类型的实例,我们都只有一个函数原型通过了substitution —— 这样就保证了它的“有且唯一”,编译器也不会因为你某个替换失败而无视成功的那个实例。
这个例子说到了这里,熟悉C++的你,一定会站出来说我们只要把第一个签名改成:
void inc_counter(ICounter& counterObj);就能完美解决这个问题了,根本不需要这么复杂的编译器机制。
嗯,你说的没错,在这里这个特性一点都没用。
这也提醒我们,当你觉得需要写 enable_if 的时候,首先要考虑到以下可能性:
- 重载(对模板函数)
- 偏特化(对模板类而言)
- 虚函数
但是问题到了这里并没有结束。因为 increase 毕竟是个虚函数。假如 Counter 需要调用的地方实在是太多了,这个时候我们会非常期望 increase 不再是个虚函数以提高性能。此时我们会调整继承层级:
struct ICounter {};
struct Counter: public ICounter {
void increase() {
// impl
}
};那么原有的 void inc_counter(ICounter& counterObj) 就无法再执行下去了。这个时候你可能会考虑一些变通的办法:
template <typename T>
void inc_counter(ICounter& c) {};
template <typename T>
void inc_counter(T& c) { ++c; };
void doSomething() {
Counter cntObj;
uint32_t cntUI32;
// blah blah blah
inc_counter(cntObj); // 1
inc_counter(static_cast<ICounter&>(cntObj)); // 2
inc_counter(cntUI32); // 3
}对于调用 1,因为 cntObj 到 ICounter 是需要类型转换的,所以比 void inc_counter(T&) [T = Counter] 要更差一些。然后它会直接实例化后者,结果实现变成了 ++cntObj,BOOM!
那么我们做 2 试试看?嗯,工作的很好。但是等等,我们的初衷是什么来着?不就是让 inc_counter 对不同的计数器类型透明吗?这不是又一夜回到解放前了?
所以这个时候,就能看到 enable_if 是如何通过 SFINAE 发挥威力的了:
#include <type_traits>
#include <utility>
#include <cstdint>
struct ICounter {};
struct Counter: public ICounter {
void increase() {
// impl
}
};
template <typename T> void inc_counter(
T& counterObj,
typename std::enable_if<
std::is_base_of<ICounter, T>::value
>::type* = nullptr ){
counterObj.increase();
}
template <typename T> void inc_counter(
T& counterInt,
typename std::enable_if<
std::is_integral<T>::value
>::type* = nullptr ){
++counterInt;
}
void doSomething() {
Counter cntObj;
uint32_t cntUI32;
// blah blah blah
inc_counter(cntObj); // OK!
inc_counter(cntUI32); // OK!
}这个代码是不是看起来有点脏脏的。眼尖的你定睛一瞧,咦, ICounter 不是已经空了吗,为什么我们还要用它作为基类呢?
这是个好问题。在本例中,我们用它来区分一个counter是不是继承自ICounter。最终目的,是希望知道 counter 有没有 increase 这个函数。
所以 ICounter 只是相当于一个标签。而于情于理这个标签都是个累赘。但是在C++11之前,我们并没有办法去写类似于:
template <typename T> void foo(T& c, decltype(c.increase())* = nullptr);这样的函数签名,因为假如 T 是 int,那么 c.increase() 这个函数调用就不存在。但它又不属于Type Failure,而是一个Expression Failure,在C++11之前它会直接导致编译器出错,这并不是我们所期望的。所以我们才退而求其次,用一个类似于标签的形式来提供我们所需要的类型信息。以后的章节,后面我们会说到,这种和类型有关的信息我们可以称之为 type traits。
到了C++11,它正式提供了 Expression SFINAE,这时我们就能抛开 ICounter 这个无用的Tag,直接写出我们要写的东西:
struct Counter {
void increase() {
// Implements
}
};
template <typename T>
void inc_counter(T& intTypeCounter, std::decay_t<decltype(++intTypeCounter)>* = nullptr) {
++intTypeCounter;
}
template <typename T>
void inc_counter(T& counterObj, std::decay_t<decltype(counterObj.increase())>* = nullptr) {
counterObj.increase();
}
void doSomething() {
Counter cntObj;
uint32_t cntUI32;
// blah blah blah
inc_counter(cntObj);
inc_counter(cntUI32);
}此外,还有一种情况只能使用 SFINAE,而无法使用包括继承、重载在内的任何方法,这就是Universal Reference。比如,
// 这里的a是个通用引用,可以准确的处理左右值引用的问题。
template <typename ArgT> void foo(ArgT&& a);假如我们要限定ArgT只能是 float 的衍生类型,那么写成下面这个样子是不对的,它实际上只能接受 float 的右值引用。
void foo(float&& a);此时的唯一选择,就是使用Universal Reference,并增加 enable_if 限定类型,如下面这样:
template <typename ArgT>
void foo(
ArgT&& a,
typename std::enabled_if<
std::is_same<std::decay_t<ArgT>, float>::value
>::type* = nullptr
);从上面这些例子可以看到,SFINAE最主要的作用,是保证编译器在泛型函数、偏特化、及一般重载函数中遴选函数原型的候选列表时不被打断。除此之外,它还有一个很重要的元编程作用就是实现部分的编译期自省和反射。
虽然它写起来并不直观,但是对于既没有编译器自省、也没有Concept的C++11来说,已经是最好的选择了。
(补充例子:构造函数上的enable_if)
!!! 以下章节未完成 !!!
4 元编程下的数据结构与算法
4.1 表达式与数值计算
4.1 获得类型的属性——类型萃取(Type Traits)
4.2 列表与数组
4.3 字典结构
4.4 “快速”排序
4.5 其它常用的“轮子”
5 模板的进阶技巧
5.1 嵌入类
5.2 Template-Template Class
5.3 高阶函数
5.4 闭包:模板的“基于对象”
stl allocator?
mpl::apply
5.5 占位符(placeholder):在C++中实现方言的基石
5.6 编译期“多态”
6 模板的威力:从foreach, transform到Linq
6.1 Foreach与Transform
6.2 Boost中的模板
Any Spirit Hana TypeErasure
6.3 Reactor、Linq与C++中的实践
6.4 更高更快更强:从Linq到FP
7 结语:讨论有益,争端无用
7.1 更好的编译器,更友善的出错信息
7.2 模板的症结:易于实现,难于完美
7.3 一些期望
alexandrescu 关于 min max 的讨论:《再谈Min和Max》
std::experimental::any / boost.any 对于 reference 的处理