分类 学习 下的文章
井字棋全解析
- 作者: thebadzhang
- 时间:
- 分类: 学习
- 评论
井字棋全解析
此博客参考:[]()
0.0
井字棋看似简单,其实蕴含了很多的玩法,但是由于太过简单,导致玩起来都是,中间,中间,中间。少了无数变化,以至于只有和棋,鲜有输赢
||||
|-|-|-|
||||
||||
一个棋盘为 3x3 的布局,双方执黑白两棋,若棋三子相连,则赢。
由于棋盘的对称,所以第一步只有三种下法,其他都是对于这个棋位对称得到。
1.1
我们采用最常见的先手-中讲起
||||
|-|-|-|
||黑||
||||
此时中心对称,对于白子,仅有两种走法,其余皆对称得到
第一种;边,无错此时白子必输
||||
|-|-|-|
||黑||
||白||
此时黑子有四种走法,两角,两边,但是走边必合
||||
|-|-|-|
||黑||
||白|黑|
白子必须走左上角拦,棋局此时已定,黑子只要下在右上角即可双杀胜利
|白|||
|-|-|-|
||黑||
||白|黑|
若黑走上对角,类似,也直接可取胜
||||
|-|-|-|
||黑|黑|
||白||
||||
|-|-|-|
|白|黑|黑|
||白||
第二种:角
||||
|-|-|-|
||黑||
|||白|
2.1
||||
|-|-|-|
||||
||黑||
3.1
||||
|-|-|-|
||||
|黑|||
线性代数的本质
- 作者: thebadzhang
- 时间:
- 分类: 编程,学习
- 评论
https://blog.csdn.net/a514371309/article/details/81604194
原文链接:https://www.cnblogs.com/TenosDoIt/p/3214096.html
从大学开始接触矩阵论和线性代数,记了很多公式,但是总感觉徘徊在线性代数的门外没有进去,感觉并没有接触到它的核心概念,不巧看到了这篇博客,顿时醍醐灌顶,豁然开朗,记录与此:
比如说,在全国一般工科院系教学中应用最广泛的同济线性代数教材(现在到了第四版),一上来就介绍逆序数这个古怪概念,然后用逆序数给出行列式的一个极不直观的定义,接着是一些简直犯傻的行列式性质和习题——把这行乘一个系数加到另一行上,再把那一列减过来,折腾得那叫一个热闹,可就是压根看不出这个东西有嘛用。
大多数像我一样资质平庸的学生到这里就有点犯晕:连这是个什么东西都模模糊糊的,就开始钻火圈表演了,这未免太无厘头了吧!于是开始有人逃课,更多的人开始抄作业。这下就中招了,因为其后的发展可以用一句峰回路转来形容,紧跟着这个无厘头的行列式的,是一个同样无厘头但是伟大的无以复加的家伙的出场——矩阵来了!多年之后,我才明白,当老师犯傻似地用中括号把一堆傻了吧叽的数括起来,并且不紧不慢地说:“这个东西叫做矩阵”的时候,我的数学生涯掀开了何等悲壮辛酸、惨绝人寰的一幕!自那以后,在几乎所有跟“学问”二字稍微沾点边的东西里,矩阵这个家伙从不缺席。对于我这个没能一次搞定线性代数的笨蛋来说,矩阵老大的不请自来每每搞得我灰头土脸,头破血流。长期以来,我在阅读中一见矩阵,就如同阿Q见到了假洋鬼子,揉揉额角就绕道走。
事实上,我并不是特例。一般工科学生初学线性代数,通常都会感到困难。这种情形在国内外皆然。瑞典数学家Lars Garding在其名著Encounter withMathematics中说:“如果不熟悉线性代数的概念,要去学习自然科学,现在看来就和文盲差不多。然而“按照现行的国际标准,线性代数是通过公理化来表述的,它是第二代数学模型,这就带来了教学上的困难。”事实上,当我们开始学习线性代数的时候,不知不觉就进入了“第二代数学模型”的范畴当中,这意味着数学的表述方式和抽象性有了一次全面的进化,对于从小一直在“第一代数学模型”,即以实用为导向的、具体的数学模型中学习的我们来说,在没有并明确告知的情况下进行如此剧烈的paradigm shift,不感到困难才是奇怪的。
大部分工科学生,往往是在学习了一些后继课程,如数值分析、数学规划、矩阵论之后,才逐渐能够理解和熟练运用线性代数。即便如此,不少人即使能够很熟练地以线性代数为工具进行科研和应用工作,但对于很多这门课程的初学者提出的、看上去是很基础的问题却并不清楚。比如说:
1、矩阵究竟是什么东西?
2、向量可以被认为是具有n个相互独立的性质(维度)的对象的表示,矩阵又是什么呢?
3、我们如果认为矩阵是一组列(行)向量组成的新的复合向量的展开式,那么为什么这种展开式具有如此广泛的应用?特别是,为什么偏偏二维的展开式如此有用?
4、如果矩阵中每一个元素又是一个向量,那么我们再展开一次,变成三维的立方阵,是不是更有用?
5、矩阵的乘法规则究竟为什么这样规定?为什么这样一种怪异的乘法规则却能够在实践中发挥如此巨大的功效?很多看上去似乎是完全不相关的问题,最后竟然都归结到矩阵的乘法,这难道不是很奇妙的事情?难道在矩阵乘法那看上去莫名其妙的规则下面,包含着世界的某些本质规律?如果是的话,这些本质规律是什么?
6、行列式究竟是一个什么东西?为什么会有如此怪异的计算规则?行列式与其对应方阵本质上是什么关系?为什么只有方阵才有对应的行列式,而一般矩阵就没有(不要觉得这个问题很蠢,如果必要,针对mxn矩阵定义行列式不是做不到的,之所以不做,是因为没有这个必要,但是为什么没有这个必要)?而且,行列式的计算规则,看上去跟矩阵的任何计算规则都没有直观的联系,为什么又在很多方面决定了矩阵的性质?难道这一切仅是巧合?
7、矩阵为什么可以分块计算?分块计算这件事情看上去是那么随意,为什么竟是可行的?
8、对于矩阵转置运算AT,有(AB)T=BTAT,对于矩阵求逆运算A-1,有(AB)-1=B-1A-1。两个看上去完全没有什么关系的运算,为什么有着类似的性质?这仅仅是巧合吗?
9、为什么说P−1AP得到的矩阵与A矩阵“相似”?这里的“相似”是什么意思?
10、特征值和特征向量的本质是什么?它们定义就让人很惊讶,因为Ax=λx,一个诺大的矩阵的效应,竟然不过相当于一个小小的数λ,确实有点奇妙。但何至于用“特征”甚至“本征”来界定?它们刻划的究竟是什么?
这样的一类问题,经常让使用线性代数已经很多年的人都感到为难。就好像大人面对小孩子的刨根问底,最后总会迫不得已地说“就这样吧,到此为止”一样,
面对这样的问题,很多老手们最后也只能用:“就是这么规定的,你接受并且记住就好”来搪塞。
然而,这样的问题如果不能获得回答,线性代数对于我们来说就是一个粗暴的、不讲道理的、莫名其妙的规则集合,我们会感到,自己并不是在学习一门学问,而是被不由分说地“抛到”一个强制的世界中,只是在考试的皮鞭挥舞之下被迫赶路,全然无法领略其中的美妙、和谐与统一。直到多年以后,我们已经发觉这门学问如此的有用,却仍然会非常迷惑:怎么这么凑巧?我认为这是我们的线性代数教学中直觉性丧失的后果。上述这些涉及到“如何能”、“怎么会”的问题,仅仅通过纯粹的数学证明来回答,是不能令提问者满意的。比如,如果你通过一般的证明方法论证了矩阵分块运算确实可行,那么这并不能够让提问者的疑惑得到解决。他们真正的困惑是:矩阵分块运算为什么竟然是可行的?究竟只是凑巧,还是说这是由矩阵这种对象的某种本质所必然决定的?如果是后者,那么矩阵的这些本质是什么?只要对上述那些问题稍加考虑,我们就会发现,所有这些问题都不是单纯依靠数学证明所能够解决的。像我们的教科书那样,凡事用数学证明,最后培养出来的学生,只能熟练地使用工具,却欠缺真正意义上的理解。
自从1930年代法国布尔巴基学派兴起以来,数学的公理化、系统性描述已经获得巨大的成功,这使得我们接受的数学教育在严谨性上大大提高。然而数学公理化的一个备受争议的副作用,就是一般数学教育中直觉性的丧失。数学家们似乎认为直觉性与抽象性是矛盾的,因此毫不犹豫地牺牲掉前者。然而包括我本人在内的很多人都对此表示怀疑,我们不认为直觉性与抽象性一定相互矛盾,特别是在数学教育中和数学教材中,帮助学生建立直觉,有助于它们理解那些抽象的概念,进而理解数学的本质。反之,如果一味注重形式上的严格性,学生就好像被迫进行钻火圈表演的小白鼠一样,变成枯燥的规则的奴隶。
对于线性代数的类似上述所提到的一些直觉性的问题,两年多来我断断续续地反复思考了四、五次,为此阅读了好几本国内外线性代数、数值分析、代数和数学通论性书籍,其中像前苏联的名著《数学:它的内容、方法和意义》、龚昇教授的《线性代数五讲》、前面提到的Encounter with Mathematics(《数学概观》)以及Thomas A. Garrity的《数学拾遗》都给我很大的启发。不过即使如此,我对这个主题的认识也经历了好几次自我否定。比如以前思考的一些结论曾经写在自己的blog里,但是现在看来,这些结论基本上都是错误的。因此打算把自己现在的有关理解比较完整地记录下来,一方面是因为我觉得现在的理解比较成熟了,可以拿出来与别人探讨,向别人请教。另一方面,如果以后再有进一步的认识,把现在的理解给推翻了,那现在写的这个snapshot也是很有意义的。
线性空间
今天先谈谈对线形空间和矩阵的几个核心概念的理解。这些东西大部分是凭着自己的理解写出来的,基本上不抄书,可能有错误的地方,希望能够被指出。但我希望做到直觉,也就是说能把数学背后说的实质问题说出来。
首先说说空间(space),这个概念是现代数学的命根子之一,从拓扑空间开始,一步步往上加定义,可以形成很多空间。线形空间其实还是比较初级的,如果在里面定义了范数,就成了赋范线性空间。赋范线性空间满足完备性,就成了巴那赫空间;赋范线性空间中定义角度,就有了内积空间,内积空间再满足完备性,就得到希尔伯特空间。总之,空间有很多种。你要是去看某种空间的数学定义,大致都是:存在一个集合,在这个集合上定义某某概念,然后满足某些性质,就可以被称为空间。这未免有点奇怪,为什么要用“空间”来称呼一些这样的集合呢?大家将会看到,其实这是很有道理的。我们一般人最熟悉的空间,毫无疑问就是我们生活在其中的(按照牛顿的绝对时空观)的三维空间,从数学上说,这是一个三维的欧几里德空间,我们先不管那么多,先看看我们熟悉的这样一个空间有些什么最基本的特点。仔细想想我们就会知道,这个三维的空间:
1.由很多(实际上是无穷多个)位置点组成;
2.这些点之间存在相对的关系;
3.可以在空间中定义长度、角度;
4.这个空间可以容纳运动,这里我们所说的运动是从一个点到另一个点的移动(变换),而不是微积分意义上的“连续”性的运动。
上面的这些性质中,最最关键的是第4条。第1、2条只能说是空间的基础,不算是空间特有的性质,凡是讨论数学问题,都得有一个集合,大多数还得在这个集合上定义一些结构(关系),并不是说有了这些就算是空间。而第3条太特殊,其他的空间不需要具备,更不是关键的性质。只有第4条是空间的本质,也就是说,容纳运动是空间的本质特征。认识到了这些,我们就可以把我们关于三维空间的认识扩展到其他的空间。事实上,不管是什么空间,都必须容纳和支持在其中发生的符合规则的运动(变换)。你会发现,在某种空间中往往会存在一种相对应的变换,比如拓扑空间中有拓扑变换,线性空间中有线性变换,仿射空间中有仿射变换,其实这些变换都只不过是对应空间中允许的运动形式而已。 因此只要知道,“空间”是容纳运动的一个对象集合,而变换则规定了对应空间的运动。 下面我们来看看线性空间。线性空间的定义任何一本书上都有,但是既然我们承认线性空间是个空间,那么有两个最基本的问题必须首先得到解决,那就是:
1.空间是一个对象集合,线性空间也是空间,所以也是一个对象集合。那么线性空间是什么样的对象的集合?或者说,线性空间中的对象有什么共同点吗?
2.线性空间中的运动如何表述的?也就是,线性变换是如何表示的?
我们先来回答第一个问题,回答这个问题的时候其实是不用拐弯抹角的,可以直截了当的给出答案:线性空间中的任何一个对象,通过选取基和坐标的办法,都可以表达为向量的形式。通常的向量空间我就不说了,举两个不那么平凡的例子:
1、L1是最高次项不大于n次的多项式的全体构成一个线性空间,也就是说,这个线性空间中的每一个对象是一个多项式。如果我们以x0,x1,...,xn为基,那么任何一个这样的多项式都可以表达为一组n+1维向量,其中的每一个分量ai其实就是多项式中xi−1项的系数。值得说明的是,基的选取有多种办法,只要所选取的那一组基线性无关就可以。这要用到后面提到的概念了,所以这里先不说,提一下而已。
2、L2是闭区间[a, b]上的n阶连续可微函数的全体,构成一个线性空间。也就是说,这个线性空间的每一个对象是一个连续函数。对于其中任何一个连续函数,根据魏尔斯特拉斯定理,一定可以找到最高次项不大于n的多项式函数,使之与该连续函数的差为0,也就是说,完全相等。这样就把问题归结为L1了。后面就不用再重复了。
所以说, 向量是很厉害的,只要你找到合适的基,用向量可以表示线性空间里任何一个对象。这里头大有文章,因为向量表面上只是一列数,但是其实由于它的有序性,所以除了这些数本身携带的信息之外,还可以在每个数的对应位置上携带信息。为什么在程序设计中数组最简单,却又威力无穷呢?根本原因就在于此。
这是另一个问题了,这里就不说了。
下面来回答第二个问题,这个问题的回答会涉及到线性代数的一个最根本的问题。线性空间中的运动,被称为线性变换。也就是说,你从线性空间中的一个点运动到任意的另外一个点,都可以通过一个线性变化来完成。那么,线性变换如何表示呢?很有意思,在线性空间中,当你选定一组基之后,不仅可以用一个向量来描述空间中的任何一个对象,而且可以用矩阵来描述该空间中的任何一个运动(变换)。而使某个对象发生对应运动的方法,就是用代表那个运动的矩阵,乘以代表那个对象的向量。简而言之,在线性空间中选定基之后,向量刻画对象,矩阵刻画对象的运动,用矩阵与向量的乘法施加运动。是的,矩阵的本质是运动的描述。如果以后有人问你矩阵是什么,那么你就可以响亮地告诉他,矩阵的本质是运动的描述。
可是多么有意思啊,向量本身不是也可以看成是n x 1矩阵吗?这实在是很奇妙,一个空间中的对象和运动竟然可以用相类同的方式表示。能说这是巧合吗?如果是巧合的话,那可真是幸运的巧合!可以说,线性代数中大多数奇妙的性质,均与这个巧合有直接的关系。
接着理解矩阵,上面说“矩阵是运动的描述”,到现在为止,好像大家都还没什么意见。但是我相信早晚会有数学系出身的网友来拍板转。因为运动这个概念,在数学和物理里是跟微积分联系在一起的。我们学习微积分的时候,总会有人照本宣科地告诉你,初等数学是研究常量的数学,是研究静态的数学,高等数学是变量的数学,是研究运动的数学。大家口口相传,差不多人人都知道这句话。但是真知道这句话说的是什么意思的人,好像也不多。
因为这篇文章不是讲微积分的,所以我就不多说了。有兴趣的读者可以去看看齐民友教授写的《重温微积分》。我就是读了这本书开头的部分,才明白“高等数学是研究运动的数学”这句话的道理。不过在我这个《理解矩阵》的文章里,“运动”的概念不是微积分中的连续性的运动,而是瞬间发生的变化。比如这个时刻在A点,经过一个“运动”,一下子就“跃迁”到了B点,其中不需要经过A点与B点之间的任何一个点。这样的“运动”,或者说“跃迁”,是违反我们日常的经验的。不过了解一点量子物理常识的人,就会立刻指出,量子(例如电子)在不同的能量级轨道上跳跃,就是瞬间发生的,具有这样一种跃迁行为。所以说,自然界中并不是没有这种运动现象,只不过宏观上我们观察不到。但是不管怎么说,“运动”这个词用在这里,还是容易产生歧义的,说得更确切些,应该是“跃迁”。因此这句话可以改成:
“矩阵是线性空间里跃迁的描述”。可是这样说又太物理,也就是说太具体,而不够数学,也就是说不够抽象。因此我们最后换用一个正牌的数学术语——变换,来描述这个事情。这样一说,大家就应该明白了,所谓变换,其实就是空间里从一个点(元素/对象)到另一个点(元素/对象)的跃迁。比如说,仿射变换,就是在仿射空间里从一个点到另一个点的跃迁。
附带说一下,这个仿射空间跟向量空间是亲兄弟。做计算机图形学的朋友都知道,尽管描述一个三维对象只需要三维向量,但所有的计算机图形学变换矩阵都是4x4的。说其原因,很多书上都写着“为了使用中方便”,这在我看来简直就是企图蒙混过关。真正的原因,是因为在计算机图形学里应用的图形变换,实际上是在仿射空间而不是向量空间中进行的。想想看,在向量空间里相一个向量平行移动以后仍是相同的那个向量,而现实世界等长的两个平行线段当然不能被认为同一个东西,所以计算机图形学的生存空间实际上是仿射空间。而仿射变换的矩阵表示根本就是4x4的。有兴趣的读者可以去看《计算机图形学——几何工具算法详解》。
一旦我们理解了“变换”这个概念,矩阵的定义就变成:矩阵是线性空间里的变换的描述。到这里为止,我们终于得到了一个看上去比较数学的定义。不过还要多说几句。教材上一般是这么说的,在一个线性空间V里的一个线性变换T,当选定一组基之后,就可以表示为矩阵。因此我们还要说清楚到底什么是线性变换,什么是基,什么叫选定一组基。线性变换的定义是很简单的,设有一种变换T,使得对于线性空间V中间任何两个不相同的对象x和y,以及任意实数a和b,有:T(ax+by)=aT(x)+bT(y),那么就称T为线性变换。定义都是这么写的,但是光看定义还得不到直觉的理解。线性变换究竟是一种什么样的变换?我们刚才说了,变换是从空间的一个点跃迁到另一个点,而线性变换,就是从一个线性空间V的某一个点跃迁到另一个线性空间W的另一个点的运动。这句话里蕴含着一层意思,就是说一个点不仅可以变换到同一个线性空间中的另一个点,而且可以变换到另一个线性空间中的另一个点去。不管你怎么变,只要变换前后都是线性空间中的对象,这个变换就一定是线性变换,也就一定可以用一个非奇异矩阵来描述。而你用一个非奇异矩阵去描述的一个变换,一定是一个线性变换。
有的人可能要问,这里为什么要强调非奇异矩阵?所谓非奇异,只对方阵有意义,那么非方阵的情况怎么样?这个说起来就会比较冗长了,最后要把线性变换作为一种映射,并且讨论其映射性质,以及线性变换的核与像等概念才能彻底讲清楚。
以下我们只探讨最常用、最有用的一种变换,就是在同一个线性空间之内的线性变换。也就是说,下面所说的矩阵,不作说明的话,就是方阵,而且是非奇异方阵。学习一门学问,最重要的是把握主干内容,迅速建立对于这门学问的整体概念,不必一开始就考虑所有的细枝末节和特殊情况,自乱阵脚。
什么是基呢?这个问题在后面还要大讲一番,这里只要把基看成是线性空间里的坐标系就可以了。注意是坐标系,不是坐标值,这两者可是一个“对立矛盾统一体”。这样一来,“选定一组基”就是说在线性空间里选定一个坐标系。好,最后我们把矩阵的定义完善如下:“矩阵是线性空间中的线性变换的一个描述。在一个线性空间中,只要我们选定一组基,那么对于任何一个线性变换,都能够用一个确定的矩阵来加以描述。”理解这句话的关键,在于把“线性变换”与“线性变换的一个描述”区别开。一个是那个对象,一个是对那个对象的表述。就好像我们熟悉的面向对象编程中,一个对象可以有多个引用,每个引用可以叫不同的名字,但都是指的同一个对象。如果还不形象,那就干脆来个很俗的类比。比如有一头猪,你打算给它拍照片,只要你给照相机选定了一个镜头位置,那么就可以给这头猪拍一张照片。这个照片可以看成是这头猪的一个描述,但只是一个片面的的描述,因为换一个镜头位置给这头猪拍照,能得到一张不同的照片,也是这头猪的另一个片面的描述。所有这样照出来的照片都是这同一头猪的描述,但是又都不是这头猪本身。同样的,对于一个线性变换,只要你选定一组基,那么就可以找到一个矩阵来描述这个线性变换。换一组基,就得到一个不同的矩阵。所有这些矩阵都是这同一个线性变换的描述,但又都不是线性变换本身。
但是这样的话,问题就来了如果你给我两张猪的照片,我怎么知道这两张照片上的是同一头猪呢?同样的,你给我两个矩阵,我怎么知道这两个矩阵是描述的同一个线性变换呢?如果是同一个线性变换的不同的矩阵描述,那就是本家兄弟了,见面不认识,岂不成了笑话。好在,我们可以找到同一个线性变换的矩阵兄弟们的一个性质,那就是:若矩阵A与B是同一个线性变换的两个不同的描述(之所以会不同,是因为选定了不同的基,也就是选定了不同的坐标系),则一定能找到一个非奇异矩阵P,使得A、B之间满足这样的关系:A=P−1BP。线性代数稍微熟一点的读者一下就看出来,这就是相似矩阵的定义。没错,所谓相似矩阵,就是同一个线性变换的不同的描述矩阵。按照这个定义,同一头猪的不同角度的照片也可以成为相似照片。俗了一点,不过能让人明白。而在上面式子里那个矩阵P,其实就是A矩阵所基于的基与B矩阵所基于的基这两组基之间的一个变换关系。
关于这个结论,可以用一种非常直觉的方法来证明(而不是一般教科书上那种形式上的证明),如果有时间的话,我以后在blog里补充这个证明。这个发现太重要了。原来一族相似矩阵都是同一个线性变换的描述啊!难怪这么重要!工科研究生课程中有矩阵论、矩阵分析等课程,其中讲了各种各样的相似变换,比如什么相似标准型,对角化之类的内容,都要求变换以后得到的那个矩阵与先前的那个矩阵式相似的,为什么这么要求?因为只有这样要求,才能保证变换前后的两个矩阵是描述同一个线性变换的。
当然,同一个线性变换的不同矩阵描述,从实际运算性质来看并不是不分好环的。有些描述矩阵就比其他的矩阵性质好得多。这很容易理解,同一头猪的照片也有美丑之分嘛。所以矩阵的相似变换可以把一个比较丑的矩阵变成一个比较美的矩阵,而保证这两个矩阵都是描述了同一个线性变换。这样一来,矩阵作为线性变换描述的一面,基本上说清楚了。但是,事情没有那么简单,或者说,线性代数还有比这更奇妙的性质,那就是,矩阵不仅可以作为线性变换的描述,而且可以作为一组基的描述。而作为变换的矩阵,不但可以把线性空间中的一个点给变换到另一个点去,而且也能够把线性空间中的一个坐标系(基)表换到另一个坐标系(基)去。而且,变换点与变换坐标系,具有异曲同工的效果。线性代数里最有趣的奥妙,就蕴含在其中。理解了这些内容,线性代数里很多定理和规则会变得更加清晰、直觉。
首先来总结一下前面部分的一些主要结论:
1.首先有空间,空间可以容纳对象运动的。一种空间对应一类对象。
2.有一种空间叫线性空间,线性空间是容纳向量对象运动的。
3.运动是瞬时的,因此也被称为变换。
4.矩阵是线性空间中运动(变换)的描述。
5.矩阵与向量相乘,就是实施运动(变换)的过程。
6.同一个变换,在不同的坐标系下表现为不同的矩阵,但是它们的本质是一样的,所以本征值相同。
下面让我们把视力集中到一点以改变我们以往看待矩阵的方式。我们知道,线性空间里的基本对象是向量。
向量是这么表示的:[a1,a2,a3,...,an]。矩阵是这么表示的:a11,a12,a13,...,a1n,a21,a22,a23,...,a2n,...,an1,an2,an3,...,ann不用太聪明,我们就能看出来,矩阵是一组向量组成的。特别的,n维线性空间里的方阵是由n个n维向量组成的。我们在这里只讨论这个n阶的、非奇异的方阵,因为理解它就是理解矩阵的关键,它才是一般情况,而其他矩阵都是意外,都是不得不对付的讨厌状况,大可以放在一边。这里多一句嘴,学习东西要抓住主流,不要纠缠于旁支末节。很可惜我们的教材课本大多数都是把主线埋没在细节中的,搞得大家还没明白怎么回事就先被灌晕了。比如数学分析,明明最要紧的观念是说,一个对象可以表达为无穷多个合理选择的对象的线性和,这个概念是贯穿始终的,也是数学分析的精华。但是课本里自始至终不讲这句话,反正就是让你做吉米多维奇,掌握一大堆解偏题的技巧,记住各种特殊情况,两类间断点,怪异的可微和可积条件(谁还记得柯西条件、迪里赫莱条件...?),最后考试一过,一切忘光光。要我说,还不如反复强调这一个事情,把它深深刻在脑子里,别的东西忘了就忘了,真碰到问题了,再查数学手册嘛,何必因小失大呢?
言归正传,如果一组向量是彼此线性无关的话,那么它们就可以成为度量这个线性空间的一组基,从而事实上成为一个坐标系体系,其中每一个向量都躺在一根坐标轴上,并且成为那根坐标轴上的基本度量单位(长度1)。现在到了关键的一步。看上去矩阵就是由一组向量组成的,而且如果矩阵非奇异的话(我说了,只考虑这种情况),那么组成这个矩阵的那一组向量也就是线性无关的了,也就可以成为度量线性空间的一个坐标系。结论:矩阵描述了一个坐标系。“慢着!”,你嚷嚷起来了,“你这个骗子!你不是说过,矩阵就是运动吗?怎么这会矩阵又是坐标系了?”嗯,所以我说到了关键的一步。我并没有骗人,之所以矩阵又是运动,又是坐标系,那是因为——“运动等价于坐标系变换”。对不起,这话其实不准确,我只是想让你印象深刻。准确的说法是:“对象的变换等价于坐标系的变换”。或者:“固定坐标系下一个对象的变换等价于固定对象所处的坐标系变换。”说白了就是:“运动是相对的。”
让我们想想,达成同一个变换的结果,比如把点(1,1)变到点(2,3)去,你可以有两种做法。第一,坐标系不动,点动,把(1,1)点挪到(2,3)去。第二,点不动,变坐标系,让x轴的度量(单位向量)变成原来的1/2,让y轴的度量(单位向量)变成原先的1/3,这样点还是那个点,可是点的坐标就变成(2,3)了。方式不同,结果一样。从第一个方式来看,那就是把矩阵看成是运动描述,矩阵与向量相乘就是使向量(点)运动的过程。在这个方式下,Ma=b的意思是:“向量a经过矩阵M所描述的变换,变成了向量b。”而从第二个方式来看,矩阵M描述了一个坐标系,姑且也称之为M。那么:Ma=b的意思是:“有一个向量,它在坐标系M的度量下得到的度量结果向量为a,那么它在坐标系I的度量下,这个向量的度量结果是b。”这里的I是指单位矩阵,就是主对角线是1,其他为零的矩阵。而这两个方式本质上是等价的。我希望你务必理解这一点,因为这是本篇的关键。正因为是关键,所以我得再解释一下。在M为坐标系的意义下,如果把M放在一个向量a的前面,形成Ma的样式,我们可以认为这是对向量a的一个环境声明。它相当于是说:“注意了!这里有一个向量,它在坐标系M中度量,得到的度量结果可以表达为a。可是它在别的坐标系里度量的话,就会得到不同的结果。为了明确,我把M放在前面,让你明白,这是该向量在坐标系M中度量的结果。”
那么我们再看孤零零的向量b:b多看几遍,你没看出来吗?它其实不是b,它是:Ib也就是说:“在单位坐标系,也就是我们通常说的直角坐标系I中,有一个向量,度量的结果是b。”而Ma=Ib的意思就是说:“在M坐标系里量出来的向量a,跟在I坐标系里量出来的向量b,其实根本就是一个向量啊!”这哪里是什么乘法计算,根本就是身份识别嘛。从这个意义上我们重新理解一下向量。向量这个东西客观存在,但是要把它表示出来,就要把它放在一个坐标系中去度量它,然后把度量的结果(向量在各个坐标轴上的投影值)按一定顺序列在一起,就成了我们平时所见的向量表示形式。你选择的坐标系(基)不同,得出来的向量的表示就不同。向量还是那个向量,选择的坐标系不同,其表示方式就不同。因此,按道理来说,每写出一个向量的表示,都应该声明一下这个表示是在哪个坐标系中度量出来的。表示的方式,就是Ma,也就是说,有一个向量,在M矩阵表示的坐标系中度量出来的结果为a。
回过头来说变换的问题,我刚才说,“固定坐标系下一个对象的变换等价于固定对象所处的坐标系变换”,那个“固定对象”我们找到了,就是那个向量。但是坐标系的变换呢?我怎么没看见?请看:Ma=Ib我现在要变M为I,怎么变?对了,再前面乘以个M-1,也就是M的逆矩阵。换句话说,你不是有一个坐标系M吗,现在我让它乘以个M-1,变成I,这样一来的话,原来M坐标系中的a在I中一量,就得到b了。我建议你此时此刻拿起纸笔,画画图,求得对这件事情的理解。比如,你画一个坐标系,x轴上的衡量单位是2,y轴上的衡量单位是3,在这样一个坐标系里,坐标为(1,1)的那一点,实际上就是笛卡尔坐标系里的点(2,3)。而让它原形毕露的办法,就是把原来那个坐标系:[2,0,0,3]T 的x方向度量缩小为原来的1/2,而y方向度量缩小为原来的1/3,这样一来坐标系就变成单位坐标系I了。保持点不变,那个向量现在就变成了(2, 3)了。 怎么能够让“x方向度量缩小为原来的1/2,而y方向度量缩小为原来的1/3”呢?就是让原坐标系:[2,0,0,3] 被矩阵[1/2,0,0,1/3]T 左乘。而这个矩阵就是原矩阵的逆矩阵。
下面我们得出一个重要的结论:“对坐标系施加变换的方法,就是让表示那个坐标系的矩阵与表示那个变化的矩阵相乘。”再一次的,矩阵的乘法变成了运动的施加。只不过,被施加运动的不再是向量,而是另一个坐标系。如果你觉得你还搞得清楚,请再想一下刚才已经提到的结论,矩阵MxN,一方面表明坐标系N在运动M下的变换结果,另一方面,把M当成N的前缀,当成N的环境描述,那么就是说,在M坐标系度量下,有另一个坐标系N。这个坐标系N如果放在I坐标系中度量,其结果为坐标系MxN。
在这里,我实际上已经回答了一般人在学习线性代数是最困惑的一个问题,那就是为什么矩阵的乘法要规定成这样。简单地说,是因为:
1.从变换的观点看,对坐标系N施加M变换,就是把组成坐标系N的每一个向量施加M变换。
2.从坐标系的观点看,在M坐标系中表现为N的另一个坐标系,这也归结为,对N坐标系基的每一个向量,把它在I坐标系中的坐标找出来,然后汇成一个新的矩阵。
3.至于矩阵乘以向量为什么要那样规定,那是因为一个在M中度量为a的向量,如果想要恢复在I中的真像,就必须分别与M中的每一个向量进行內积运算。
我把这个结论的推导留给感兴趣的朋友吧。综合以上,矩阵的乘法就得那么规定,一切有根有据,绝不是哪个神经病胡思乱想出来的。我们伟大的线性代数课本上说的矩阵定义,是无比正确的:“矩阵就是由m行n列数放在一起组成的数学对象。”好了,这基本上就是我想说的全部了。
本文原文是孟岩在csdn上发表的三篇博客:理解矩阵(一),理解矩阵(二), 理解矩阵(三)
我对这篇文章的自己做的总结:
1、空间的定义都是先定义一个集合,然后在这个集合上定义一些概念和规则,就成了某某空间;“容纳运动(变换)是空间的本质!!!”
2、空间中的运动为线性变换便称为线性空间、拓扑变换便称为拓扑空间、仿射变换就称为仿射空间;一般我们说的空间有三个基本特征:
(1)空间中点的表示形式;
(2)空间中点的相对关系;
(3)空间中点的运动形式;
4、向量空间相对于线性空间还要满足内积的定义;
5、所谓相似矩阵,就是同一个线性变换的不同的描述矩阵;
3、线性空间两个最基本特征:
(1)空间中点的表示形式:线性空间中的任何一个对象,通过选取基和坐标的方法,都可以表达为向量的形式;
(2)空间中点的运动形式:线性变换(不是微积分中的连续运动,而是瞬间发生的变化,所以这里称为变换),都用矩阵来表示,矩阵的本质就是运动的描述;
继续深入,“运动是相对的”,对象的变换等价于坐标系的变换,而对于向量,它是客观存在的,要把它表示出来,需要把它放在一个坐标系中去度量;对于M*a=b这个式子,一种解释是在同一种坐标系中,向量a经过变换M运动到b处;第二种解释是在某一种坐标系下(比如称为A)的a,A坐标系经过M变换变换到B坐标系,得到的向量b是在B坐标系下度量的结果;
而我们学过的矩阵论的那些知识实际就是在研究各种变换以及它们的性质!
URI URL URN
- 作者: thebadzhang
- 时间:
- 分类: 编程,学习
- 评论
曾经我天真的以为URI和URL是一样的,只是不同叫法而已,然后某一天有人告诉我这两个不一样,so我发现是时候好好研究一下这两个概念了。
URI:Uniform Resource Identifier,统一资源标识符
URL:Uniform Resource Location统一资源定位符
它们有什么关系
URI是一个用于标识互联网资源名称的字符串。 该种标识允许用户对网络中(一般指万维网)的资源通过特定的协议进行交互操作。URI的最常见的形式是统一资源定位符(URL),经常指定为非正式的网址。更罕见的用法是统一资源名称(URN),其目的是通过提供一种途径。用于在特定的命名空间资源的标识,以补充网址。
通俗地说,URL和URN是URI的子集,URI属于URL更高层次的抽象,一种字符串文本标准。
三者关系如下图:

图示
有什么区别
上面虽然大概介绍了这两者的区别,不过感觉还是有些模糊,下面着重研究区别。
首先,URI,是统一资源标识符,用来唯一的标识一个资源。而URL是统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。而URN,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com。也就是说,URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI;
URL是URI的一种(通过那个图就看的出来吧)。但也不是所有的URI都是URL哦,就好像蝴蝶都会飞,但会飞的可不都是蝴蝶啊!
让URI能成为URL的当然就是那个“访问机制”,“网络位置”。e.g. http://
or ftp://.。URN是唯一标识的一部分,就是一个特殊的名字。
下面就来看看例子吧,当来也是来自权威的RFC:
ftp://ftp.is.co.za/rfc/rfc1808.txt (also a URL because of the protocol)
http://www.ietf.org/rfc/rfc2396.txt (also a URL because of the protocol)
ldap://[2001:db8::7]/c=GB?objectClass?one (also a URL because of the protocol)
mailto:John.Doe@example.com (also a URL because of the protocol)
news:comp.infosystems.www.servers.unix (also a URL because of the protocol)
tel:+1-816-555-1212
telnet://192.0.2.16:80/ (also a URL because of the protocol)
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
这些全都是URI, 其中有些是URL. 哪些? 就是那些提供了访问机制的.
各自的组成
- URI
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的;
URI一般由三部组成
①访问资源的命名机制
②存放资源的主机名
③资源自身的名称,由路径表示,着重强调于资源。
- URL
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL一般由三部组成
①协议(或称为服务方式)
②存有该资源的主机IP地址(有时也包括端口号)
③主机资源的具体地址。如目录和文件名等
现在,你明白了了吗,欢迎提出意见和补充哦
作者:daixinye
链接:https://www.zhihu.com/question/21950864/answer/154309494
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。拿人做例子,假设这个世界上所有人的名字都不能重复,那么名字就是URI的一个实例,通过名字这个字符串就可以标识出唯一的一个人。现实当中名字当然是会重复的,所以身份证号才是URI,通过身份证号能让我们能且仅能确定一个人。那统一资源定位符URL是什么呢。也拿人做例子然后跟HTTP的URL做类比,就可以有:动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人可以看到,这个字符串同样标识出了唯一的一个人,起到了URI的作用,所以URL是URI的子集。URL是以描述人的位置来唯一确定一个人的。在上文我们用身份证号也可以唯一确定一个人。对于这个在杭州的张三,我们也可以用:身份证号:123456789来标识他。所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URl的一种实现,而URL就是用定位的方式实现的URI。回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适,不过这样子的话还得想办法找到这个资源咯…发布于 2017-03-29赞同 98357 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续张晓杰程序员101 人赞同了该回答URI 在于I(Identifier)是统一资源标示符,可以唯一标识一个资源。URL在于Locater,一般来说(URL)统一资源定位符,可以提供找到该资源的路径,比如http://www.zhihu.com/question/21950864,但URL又是URI,因为它可以标识一个资源,所以URL又是URI的子集。举个是个URI但不是URL的例子:urn:isbn:0-486-27557-4,这个是一本书的isbn,可以唯一标识这本书,更确切说这个是URN。总的来说,locators are also identifiers, so every URL is also a URI, but there are URIs which are not URLs.编辑于 2014-08-06赞同 1016 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续wuxinliulei做好自己136 人赞同了该回答从JDK1.5开始,http://java.net包对统一资源定位符(uniform resource locator URL)和统一资源标识符(uniform resource identifier URI)作了非常明确的区分。(1)URI是个纯粹的句法结构,用于指定标识Web资源的字符串的各个不同部分。URL是URI的一个特例,它包含了定位Web资源的足够信息。其他URI,比如mailto:cay@horstman.com 则不属于定位符,因为根据该标识符无法定位任何资源。URI 是统一资源标识符,而 URL 是统一资源定位符。因此,笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。 URI 和 URL 概念上的不同反映在此类和 URL 类的不同中。 此类的实例代表由 RFC 2396 定义的语法意义上的一个 URI 引用。URI 可以是绝对的,也可以是相对的。对 URI 字符串按照一般语法进行解析,不考虑它所指定的方案(如果有)不对主机(如果有)执行查找,也不构造依赖于方案的流处理程序。相等性、哈希计算以及比较都严格地根据实例的字符内容进行定义。换句话说,一个 URI 实例和一个支持语法意义上的、依赖于方案的比较、规范化、解析和相对化计算的结构化字符串差不多。 作为对照,URL 类的实例代表了 URL 的语法组成部分以及访问它描述的资源所需的信息。URL 必须是绝对的,即它必须始终指定一个方案。URL 字符串按照其方案进行解析。通常会为 URL 建立一个流处理程序,实际上无法为未提供处理程序的方案创建一个 URL 实例。相等性和哈希计算依赖于方案和主机的 Internet 地址(如果有);没有定义比较。换句话说,URL 是一个结构化字符串,它支持解析的语法运算以及查找主机和打开到指定资源的连接之类的网络 I/O 操作。在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。相反的是,URL类可以打开一个到达资源的流。因此URL类只能作用于那些 Java类库知道该如何处理的模式,例如http:,https:,ftp:,本地文件系统(file:),和Jar文件(jar:)。URI—Uniform Resource Identifier通用资源标志符Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的URI一般由三部组成①访问资源的命名机制②存放资源的主机名③资源自身的名称,由路径表示,着重强调于资源。URL—Uniform Resource Location统一资源定位符URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成①协议(或称为服务方式)②存有该资源的主机IP地址(有时也包括端口号)③主机资源的具体地址。如目录和文件名等应用:一 、 URI比如在JDK中sun公司提供的简易HttpServer实现中public void handle(final HttpExchange exchange)throws Exception方法中,根据exchange对象可以拿到访问Http请求的URI对象,ps:http://127.0.0.1:8080/cmd_helloworld/?name=guowuxin此时URI uri = exchange.getRequestURI();通过uri可以拿到连接的各部分内容: uri.getPath() --------------------> /cmd_helloworld 注意有斜杠uri.getQuery()----------------------> name=guowuxin当然如果是post请求,请求内容在请求body当中二、 URL 上面说了,URL 是一个结构化字符串,它支持解析的语法运算以及查找主机和打开到指定资源的连接之类的网络 I/O 操作。重要的,URL不仅仅可以进行语法解析运算,还可以查找主机,并且打开指定资源的连接进行网络IO操作。介绍URL类的两个重要方法openStream() 打开到此 URL 的连接并返回一个用于从该连接读入的 InputStream。openConnection() 返回一个 URLConnection 对象,它表示到 URL 所引用的远程对象的连接。 URL url = new URL("http://www.baidu.com");
InputStream in = url.openStream();
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while ((len = in.read(buffer)) != -1)
{
output.write(buffer, 0, len);}
System.err.println(new String(output.toByteArray()));上面的程序通过openStream()方法获取访问URL获取的输入流,从而读取响应内容,ps响应内容是过滤掉响应头了的。openConnection()方法就可以getOutputStream()以及 getInputStream()可以更灵活的进行request和response编辑于 2019-02-15赞同 13612 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续Octocat52 人赞同了该回答URI可被视为定位符(URL),名称(URN)或两者兼备。统一资源名(URN)如同一个人的名称,而统一资源定位符(URL)代表一个人的住址。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。URL是一种URI,它标识一个互联网资源,并指定对其进行操作或获取该资源的方法。可能通过对主要访问手段的描述,也可能通过网络“位置”进行标识。例如,http://www.wikipedia.org/这个URL,标识一个特定资源(首页)并表示该资源的某种形式(例如以编码字符表示的,首页的HTML代码)是可以通过HTTP协议从http://www.wikipedia.org这个网络主机获得的。URN是基于某命名空间通过名称指定资源的URI。人们可以通过URN来指出某个资源,而无需指出其位置和获得方式。资源无需是基于互联网的。例如,URN urn:isbn:0-395-36341-1 指定标识系统(即国际标准书号ISBN)和某资源在该系统中的唯一表示的URI。它可以允许人们在不指出其位置和获得方式的情况下谈论这本书。引用自https://zh.wikipedia.org/wiki/%E7%BB%9F%E4%B8%80%E8%B5%84%E6%BA%90%E6%A0%87%E5%BF%97%E7%AC%A6简单理解是这样的:理解URI和URL的区别,我们引入URN这个概念。URI = Universal Resource Identifier 统一资源标志符URL = Universal Resource Locator 统一资源定位符URN = Universal Resource Name 统一资源名称这三者的关系如下图: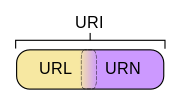 也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。
也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。
同样的,URN(统一资源名称)也是URI的一个子集,目前没有大规模运用。PS:
URI是一个字符串格式规范 并没有指定它的用途URL是资源定位的规范 包括网址 ftp服务器 文件路径编辑于 2016-08-30赞同 848 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续张磊不知学之14 人赞同了该回答Mozilla官方解释的特别好。标识互联网上的内容发布于 2017-10-13赞同 14添加评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续高洪涛习惯决定命运6 人赞同了该回答有篇感觉还不错的文章,我翻译了下,有兴趣的可以看下:[译]URL和URI的区别发布于 2015-08-12赞同 6添加评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续陆垠宇韶华散尽春已去 河风吹老少年郎.(●'◡'●)7 人赞同了该回答URI字段:指浏览器输入域名/开始后的内容,如http://www.abc.com.cn/aaa,URI字段为/aaa;HOST字段:指浏览器输入地址http://之后URI/之前的内容,如http://www.abc.com.cn/cba/aaa.php HOST字段为www.abc.comURL-HOST=URI.(●'◡'●)发布于 2018-01-31赞同 72 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续猫头佛PHP/运维/健身/读书2 人赞同了该回答参考了 @daixinye 的答案,又看了一些资料,自己总结了一下,希望有帮助吧。画图说明URI(Uniform Resource Identifier,统一资源标识符):一个资源的唯一标识,可以是一个名字、一串编号、一个URL(说明URL是一种URI)......URL(Uniform Resource Locator,统一资源定位符):一个资源的网络地址格式一般是:网络协议://域名/子目录[/子目录.....]/文件名[.文件名后缀]例子https://www.zhihu.com/question/21950864http://example.com/mypage.htmlftp://example.com/download.zipmailto:user@example.comfile:///home/user/file.txttel:1-888-555-5555http://example.com/resource?fo…/other/link.html (相对URL,仅在另一个URL的语境下有用)两者关系URI负责识别,URL负责定位URL是URI的子集(URL一定是URI,但URI不一定是URL)URI是一个唯一字符串URL是一个表示位置(或地址)的唯一字符串举例说明我要找到这个骚扰如花的油腻大叔!谁能提供他的信息?普通URI的告知方式他的身份证号是442736199706268734 或者这是他的指纹图案 或者这是他的DNA检测报告URL(一种特殊的URI)的告知方式动物住址协议://地球/中国/广东省/深圳市/南山区/XX小区/X栋X座24楼/5号座位/陈狗蛋.人(例子参考:HTTP 协议中 URI 和 URL 有什么区别?)引申领域:URI还有其他种类,类似于URN、URC......这些平时接触不多,有兴趣的可以自己另外寻找文章了解一下画图说明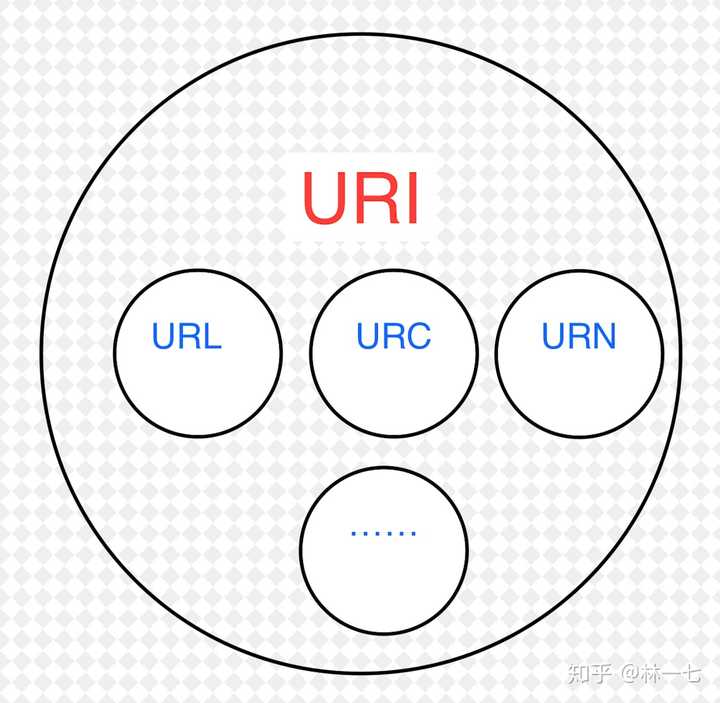 编辑于 2019-12-11
编辑于 2019-12-11
《C++ Primer》5th 读书笔记
- 作者: thebadzhang
- 时间:
- 分类: 学习
- 评论
《C++ Primer》5th 读书笔记
虽然说是这本书的笔记,但是还是会引入一些书外面的概念和新版标准的部分内容
对于不属于这本书的特殊的地方我会额外加以标注
[TOC]
第 1 章 开始
C++ 超级基础,
可以看我之前写的关于c++的必知必会的文章
UB(Undefined-Behaviors) 未定义行为
char 是 signed char 还是 unsigned char 是未定义的
int 是大于等于 short 小于等于 long 的
流
流可以作为 condition,用于判断是否到了流末尾,当到达流末尾时为 false,所以我们经常可以看到如下的写法
int n;
while (std::cin >> n) {
// do somthing...
}此时调用了 std::cin 类的 >> 函数,往 n 中输入数据,返回的是 std::cin 类的 istream 对象,到达流末尾时(通常这个标记为 EOF(End-Of-File)),在windows上可通过 Ctrl-z 和 Ctrl-d 输入 EOF 符号,标志流结束。
>> 作为一个函数,同理
std::cout << "Hello World" << std::endl;的 << 也是一个函数,但是你会发现,其中存在多次调用,因为 std::cout<< 的返回值是一个 ostream 对象,即 std::cout 本身,所以实现了上面这样子的连续调用,但实际上,这个操作可以像下面这样分解,
std::cout << "Hello World";
std::cout << std::endl;这两种写法是完全等价的,于是就引出了一个问题,线程安全,因为,这个操作可以被等价分成两份,所以它的操作是不原子的,就可能在别的线程中,被插入,造成输出顺序混乱,比如输出了
Hello World123123\n但是你想要输出的是
Hello World\n123123其中,上面的\n的是转义字符,让换行看起来更加明显。解决办法也是有的,使用原子锁,但是这个内容是在后面学习多线程时才会讲到的,所以这里不加以赘述。
字面量
字面量大致可以分为两种,一种是语言提供的字面量,一种是库提供的字面量
语言提供的字面量,例如(其实我也没有仔细研究过具体哪些属于哪些,反正把自己知道的都列出来了)
// 指针字面量
nullptr;
// 布尔字面量
true;false;
// 整数字面量
auto a = 1; // int a
auto b = 0x1; // int b
auto c = 01; // int c
// 二进制字面量在 c++14 中引入
auto d = 0b1; // int d
auto e = 1u; // unsigned int e
auto f = 1ll; // long long f
auto uf= 1ull; // unsigned long long f
auto g = 1l; // long g
// 其实这些后缀大小写都是可以的,为了方便书写,这里都写小写
// 浮点数字面量
auto h = 1.0l; // long double h
auto i = 1e-1; // double i
auto j = 1.0f; // float j
auto k = 1e-1f; // float k
// 字符(串)字面量
auto l = "Hello"; // const char *l
auto m = u"World"; // const char16_t *m
auto n = U"你好"; // const char32_t *n
auto o = u8"世界"; // const char8_t *o
auto p = L'!'; // wchar_t p
auto q = '!'; // char q但实际上,部分字面量会根据自己的数据大小自动变更数据类型,如果数据超过了long所能承载的范围,就会自动变为 long long,类型都是所能承受的最小类型,当然,char和short不在此列;
用户自定义字面量
使用运算符重载的方式
auto operator"" end(something) {
}就可以弄一个 somethingend 的一个字面量,something 作为参数传入 函数,处理后返回
第 I 部分 C++ 基础
第 2 章 变量和基本类型
初始化与赋值
其实这个是老生常谈的问题了,因为总是有非常多的事情,在这个上面纠结
int a = 10; // mov DWORD PTR [rbp-4], 10
int b; //
int d = a; // mov eax, DWORD PTR [rbp-4]
// mov DWORD PTR [rbp-8], eax
int c = b; // mov eax, DWORD PTR [rbp-12]
// mov DWORD PTR [rbp-16], eax
b = 10; // mov DWORD PTR [rbp-12], 10左侧为 c++ 代码,右侧为生成的汇编。这就很神奇了,你发现第二行定义变量 b 的时候,没有生成任何代码。在你尝试书写
int a = 10; // mov DWORD PTR [rbp-4], 10
int b; //
b = 10; // mov DWORD PTR [rbp-12], 10如上的代码的时候,生成的汇编也只有两行,就算你开 -O0 也一样,因为这个定义的语句,的确,什么事情也没有干,只是告诉编译器,「这个位置我占掉了,虽然里面的东西我没有明确给它,但是我占了,你得让接下来的变量都往后挪挪,而且不能说我不在」的这种状态。
类型、限定符、修饰符
int, char, short, long, long long, float, double, long double 等被称为基础数据类型,一切的一切基于此而产生
分析一个变量的具体类型,应该从右王座看,看到 & 就是引用类型,看到 [] 就是数组类型,看到 *就是指针类型,然后看 顶层const还是底层const
人们喜欢讨论 * 这个字符用于限定变量的时候的位置,就会产生下面三种结果
int *p1; // *p1 的类型为 int
int * p1; // 两边各退一步
int* p1; // p1 的类型为 int*我个人倾向于使用 int* 的方式,将其作为一整个类型,因为 c++ 的类型系统过于复杂,比如
int x = 20;
int* px = &x;
decltype(x) px2 = px;如果说是 *p 的类型为 type 的话,应当如何解释 decltype(x) 所推断出来的类型?所以,我倾向于使用 type* name,auto px3 = px;也是如此,如果不是类型,何来「类型推断」?
同理,引用类型也是这样
// 指针
type* name1;
// 引用
(type*)& name2 = name1;
// 上面这个是对于指针类型的引用,引用必须要初始化下面讲讲关于 const 和 constexpr
在此之前,真正的 constant 实际上是使用 #define 来定义的,但是 c++11 出现了 constexpr,终于可以用正经的方式定义一个真正的 constant 了。
constexpr 要求变量或者表达式的值能够在编译器得到计算,于是乎,用 constexpr 修饰的变量,是一个定值
const 所代表的是,不变量,与变量相对,只是在使用的过程中不会发生变化,但不代表它是一个固定的值
int a;
std::cin >> a;
const int b = a;合法么,合法,但是 b 的值会随着我们的输入而发生变化,但是在接下来试图改变b的值,都会造成编译器错误。
但其实也不一定的,虽然说不能直接通过b修改b所对应的对象值,但是我们可以通过间接的方式,访问到b,并修改,而且不会引发编译器错误。
这个我们可以拿 nim 中类似的语句进行对比
const str = "Hello World"
# Mutable variables
var c: int
c = 20
# Immutable variables
let e = cnim 中
const 是常量,var 是变量,let 是不可变量
c++ 中
constexpr 是常量,没有限定符的各种类型 是变量,const 是不可变量
这样一比其实也不难发现 c++ 在发展上的滞后性了
const int i = 20;
// 不能修改的 int 类型变量(不变量也是不会变的变量)
const int* const pi = &i;
// 首先,a 是 const,a 本身的值不能改动
// 其次,是 const int* 类型,代表是 cosnt int 类型的指针
// 说明 a 所指向的对象是 int 且不能修改
const int*& const rpi = pi;
// 一个 const int* 类型的引用,且本身也不能修改,(虽然说引用本来就不能改,不知道加上有没有我们再加上一个数组类型,数组类型就非常有趣了,因为其中的矛盾点实在太多了,比如可以弱化成指针,这一点就很折磨人,所以和别人解释,但是这个内容再在下一章解释
自动类型推断
auto
decltype(statment)
decltype(auto) //c++17 引进自定义数据结构,使用 struct 将各种数据归为一类,
但是好像没有看到 union 这个数据结构在这本书中被介绍
虽然说用的少,但其实,还是很有用的,比如用作动态类型的数据结构
第 3 章 字符串、向量和数组
其实这一章前面部分没有什么特别重要的事情,只不过介绍了 std::string 和 std::vector 两个标准库「容器」
我想这个内容可能看 C++ 标准库 可能更加适合一些
但有一点可以注意的就是
std::vector<std::string> a(10, "20");
std::vector<std::string> b{10, "20"};的效果是一样的
迭代器
std::string::itrator;
std::vector<int>::itrator;数组
int a[10];
using int10 = int[10];
int10 b;第 4 章 表达式
提升,转换,重载,左右值
赋值,取址,解引用和下标……
都必须要使用左值,
decltype 对左值,取到的是一个引用,但对于右值,取到的是本来的类型
这个在之前的例子中有出现过
int i = 10;
int* pi = &i;
decltype (*pi) d = i; // 实际上这是 int& 类型
decltype (pi) e = pi; // 这个是 int* 类型sizeof int
sizeof (1+1)int a = f1() + f2();像上面这两个函数返回值相加,但是你没有办法知道先执行的是哪一个函数,这个是不确定的,一定程度上也是线程不安全的
T operator+(const T &a, const T2 &b);同理,因为加号会图上面这样子重载,对于某一个类型的重载,你也可以把int类型的+重载成*,这个以后再讲。f1和f2就成为了 operator+ 的两个参数,这样同样表明,函数作为函数参数时,其运行顺序也是不确定的
取余的运算比较复杂,日后重新罗列
第 5 章 语句
if
if-else
for
for
while
do-while
switch
break
continue
goto
throw
try
catch
第 6 章 函数
const 的故事到这里,才算真正地开始……
整个 c++11 就是一个类型斗争史,auto,decltype,template,using,透露出两个字,类型,类型,还是类型,函数重载、尾置返回、左值引用、右值引用也涉及到类型推断,
尾置返回类型
auto func (int i) -> int(*)[10];函数参数中的顶层 const 会被忽略掉
void func (const int i);
void func (int i);上面两个声明其实都是一个函数,会报错
void print (const int* i);
void print (const int i[]);
void print (const int i[10]);上面三种声明,也是一样的,所以,在作为函数参数的时候,数组会弱化为指针
const int& i = 41;void func (int& ar[]); // 引用的数组
void func (int (&ar)[]); // 数组的引用函数返回数组指针
int (*function(void))[10]; // 一个返回指向 int[10] 的指针的函数
// 使用尾置返回
auto function(void) -> int(*)[10];
using pi10 = int(*)[10];
pi10 function (void);函数返回函数指针
int (*function (void)) (int*, int);
auto function(void) -> int(*)(int*,int);
using ifpii = int(*)(int*, int);
ifpii function (void);关于如何向数组传入长度参数,其实还有别的小妙招
template <typename T>
void func (int& ar[T]) {
}type (*function(parameters))[dimension] {
}可以定义一个返回 数组的指针 的函数
折叠表达式(C++17 起)
template<typename... Args>
bool all(Args... args) { return (... && args); }
template<typename... Args>
bool any(Args... args) { return (... || args); }
template<typename... Args>
bool sum(Args... args) { return (... + args); }
bool b = all(true, true, true, false);
// 在 all() 中,一元左折叠展开成
// return ((true && true) && true) && false;
// b 为 false
// 将一元折叠用于零长包展开时,仅允许下列运算符:
// 1) 逻辑与(&&)。空包的值为 true
// 2) 逻辑或(||)。空包的值为 false
// 3) 逗号运算符(,)。空包的值为 void()
// 注解
// 若用作 初值 或 形参包 的表达式在顶层具有优先级低于转型的运算符,则它可以加括号:
template<typename ...Args>
int sum(Args&&... args) {
// return (args + ... + 1 * 2); // 错误:优先级低于转型的运算符
return (args + ... + (1 * 2)); // OK
}函数重载匹配其实也是一个很复杂的问题,
但是拒绝认识它也是可以的,就是不要写出具有歧义的重载函数
第 7 章 类
访问控制
public private protect
友元
friend
类成员
作用域和名字查找
构造函数初始化列表
委托构造函数
默认构造函数
=default =delete
隐式类类型转换
explicit
第 II 部分 C++ 标准库
第 8 章 IO 库

| 头文件 | 类型 | 描述 |
|---|---|---|
| iostream | istream, wistream | 从流读入数据 |
| ostream, wostream | 向流写入数据 | |
| iostream, wiostream | 读写流 | |
| fstream | ifstream, wifstream | 从文件流读入数据 |
| ofstream, wofstream | 向文件流写入数据 | |
| fstream, wfstream | 文件读写流 | |
| sstream | istringstream, wistringstream | 从 string 读入数据 |
| ostringstream, wostringstream | 向 string 写入数据 | |
| stringstream, wstringstream | 读写 string |
c++ 定义了上面这些流操作的类型,提供了最基础的流抽象功能,其他功能也可以基于此进行更深的抽象
但是,C++ 的流可能是一个非常失败的设计,因为输入输出的符号大家都不是很喜欢,而且在前期缺少合适的文本格式化工具,直到 c++20 引入了 format 库,才有所改观,但实际上现在没有任何一家的编译器是支持 format 库的再者是自带的 STL 库都没有提供对于标准化输入输出流的支持,只能自己手动输入输出。
但是我们也可以通过这个设计实现一个统一的输入输出操作
可以通过若干种标志判断当前流的状态处于失败、结尾、正常或者是异常
也可以通过对应的函数设置当前的状态
unitbuf, nounitbuf, flush, endl
立即刷新,不立即刷新,强制刷新,强制刷新并换行
我们可以使用 fstream 完成对文件流的读写操作,其具体操作与输入输出流并没有特别多的区别,唯一的是需要指明文件的路径和打开方式
需要注意的是,文件的写操作默认是附带 std::ios::trunc 的,这个意味着打开一个文件的时候,如果原先存在文件,则会将原先的文件删除
使用 stringstream 则可以对流进行细分,在实际使用中出现频率还是很高的
第 9 章 顺序容器
| 顺序容器主要有 | 类型 | 介绍 |
|---|---|---|
| vector | 动态数组,即长度可变,支持快速随机访问,数据连续存储,所以插入数据可能很慢 | |
| deque | 双向队列,长度可变,支持快速随机访问,头尾插入删除很快,数据连续存储的同时分块存储 | |
| list | 双向链表,长度可变,随机访问并不快速,任意一个元素的插入删除都很快,就链表的存储方式 | |
| forward_list | 单向链表,长度可变,随机访问也不快速,但是相比双向链表少了一个方向,所以在插入和删除时比自己手写的链表快不了多少 | |
| array | 静态数组,长度不可变,可以看作是原生数组的高级版本 | |
| string | 和vector类似,但是专门用于保存字符,同时提供大量字符串处理相关的函数 | |
| queue | 单向队列,由双向队列继承而来 | |
| priority_queue | ||
| stack | 栈,由双向队列继承而来 |
其实这里有一个很巧妙的点,为什么说是快速随机访问呢,确实,链表因为数据结构的问题,其实不支持随机访问,但是可以通过遍历的方式,实现一个非常慢速的随机访问,但也其实,可以通过一个vector存储链表的迭代器,再对vector随机访问,就可以实现对链表的随机访问了,这个适用于大规模的对于链表的随机访问
同时,这些容器库之所以要叫容器库,是因为它们提供了对任意类型的「容」,这个得益于 c++ 复杂的模板,在编译器对各种类型进行展开,同时,由于模板的存在,很多本来看上去很正常的名字,就变得极为不正常了,这也导致使用了模板的报错变得异常难读,学会从模板报错中找到正确的错误,也是一个非常重要的技巧
这些容器库,STL,都包含着若干统一的操作函数,但这里就不一一列举了,这不应该成为学习 c++ 的负担。诸如比较,构造,复制,交换,添加删除,以及各类迭代器(c++11 引入了一种新的反迭代器,还有各种容器的构造,赋值,交换,追加,插入,删除,移动,拷贝,这里也不加以细说。
往容器中添加元素又变得非常有复杂,但也没有那么复杂
push_back, push_front, emplace_back, emplace_front, insert,其中 emplace 系列函数于 c++11 引入,究其原因还是因为 c++11 带来的右值引用,push 系列函数在插入一个值的时候,会先对值进行拷贝,但是 emplcae 函数借用右值引用直接将值写入对应位置,减少了一次拷贝,一定程度上提升了性能(右值引用牛逼!)
https://zhuanlan.zhihu.com/p/213853588
pop_back, pop_front, erase 用于删除元素
各个迭代器的使用,forward_list独树一帜的特殊操作
对于容器的插入删除可能导致迭代器失效,因为移动了容器中实际内容的位置,vector在内容将要填满预先分配的空间时,会将当前空间扩大为两倍,使用capacity可以查看已分配的空间,size查看已使用的空间
对字符串的各种操作函数在这里也不加以赘述了,实际上字符串库应当搭配c++11引入的regex正则匹配库和c++20引入的format格式化库使用更加顺手,正则匹配是一个好东西,就是看起来效率非常差,但也没有那么差了
第 10 章 泛型算法
泛型,何为泛型,即通用的,对于任何类型都可以使用,类型无关
这些泛型函数主要通过迭代器和传入的函数进行使用
其中大多数函数定义在 algorithm 算法库中,c++11 提供了超过一百种的内置算法,为开发提供了非常有用的帮助,尤其是 sort 函数我使用的次数不可谓不多
find, find_if...
(我会在将来的某天详细地介标准库的内容,但不会是在这本书上
泛型算法主要分为只读算法,写算法和排序算法
查找算法,判断算法等算法为只读算法
写算法,插入算法(使用插入迭代器),拷贝算法(利用迭代器),
排序算法,sort不稳定排序,stable_sort稳定排序,性能上各有千秋
之后,这本书在这个地方介绍了一个非常重量的 c++11 更新,lambda 函数,同时,这也更一步的让c++拥有了函数式编程的风范,一个较为简单的方式声明并使用一个函数,其中的详细内容我会另开一个文章进行介绍,但书中没有在这里引入function函数用来存储lambda函数我感觉还是有些欠妥当,不过也介绍了bind函数关于绑定函数参数的内容,同时介绍了find_if 函数和for_each 函数。值捕获,引用捕获,隐式捕获,等等等等,设置返回值,自动推断返回值,这里甚至还产生了闭包,但是在这本书里貌似没有介绍到。在lua中,闭包是一个非常重要的概念,而且在介绍lua的书中大书特书了
这里详细介绍了插入迭代器和反迭代器
第 11 章 关联容器
1)set or map 2)可否重复 3)有无顺序
因此产生了八种不同的数据类型,分别是:set map multiset multimap unordered_map unordered_set unordered_multimap unordered_multiset
因为map存储了两个信息,这里还引入了一个新的对象 pair,用于构成一对的数据结构,分别存储 map的key和value。关联容器同样拥有普通容器的大部分操作。之所以叫做关联,是因为key之间是相互影响的。比如在map和set中,是不允许出现相同的key的,这叫关联。
关联容器可以使用任意类型当作key和value,总之非常有用,但是具体的操作并不在这里赘述。一个非常有用的地方,就是统计单词的数量和有多少种单词,map的key为单数,value为数量,即可进行统计。set的key为单词,即可统计单词的种类,因为set在数学上与集合的含义相类似,所以在这里其实对于set还有非常多的集合操作,这本书上也没有讲。
然后我也没什么好讲的了,毕竟关于标准库的介绍不应该成为负担
第 12 章 动态内存
从程序支持手动申请内存开始,人类就陷入了无限的与指针的抗争之中。人们为了正确处理这些内存,掉了数不清的头发。所有分配的对象,需要一个能够指向它们的指针才能调用。手动分配的对象不受作用域或者生命周期影响。但是用来存储这个指针的对象,存在作用域和生命周期,当语句块结束后,这个指针变量则会消失,也许指针变成返回值传到另一个变量之中,也许没有。如果没有的话,那么这个内存中的对象就彻底变得无主了,于是这个内存中的对象就无法已正常地形式进行清除了。
这就形成了垃圾,于是我们引入了垃圾回收的概念,这个在相当多的语言中都有直接的体会,但是,这么方便为什么c++不用呢?因为垃圾回收,浪费空间,也浪费性能,所以这个功能不会在c++中提供,诸如python和lua,会对一些垃圾自动「标记-清理」。如果尝试写python,循环地进行一些事项,你有可能发现自己的内存占用,忽高忽低,这个就是python垃圾回收的效果了。
智能指针
但是c++难道没有办法高效地实现垃圾回收了么?当然是有的。答案就是使用智能指针,智能指针是在C++11中引入的。既然问题出现在指针上,那么解决这个指针,那么所有的问题就迎刃而解了。借助 c++ 类所带来的 RAII 功能,我们可以轻松实现,创建时如何,销毁时如何的功能。这也为智能指针的出现,奠定了基础。
智能指针分为三类
shared_ptr
unique_ptr
weak_ptr
其中,shared_ptr可以被赋值,拷贝,即可以存在多份,每次赋值拷贝会调用对应的构造函数,返回这样一个指针也会产生拷贝。每一次执行上述的操作时,其内部的计数器,会让自己的值增加一,只要内部计数器的值达到零,就会自动销毁内存中的对象。当然,这个时候,智能指针对象也肯定不会存在的。其中,weak_ptr是不会增长这个计数器,但是,当目标对象被销毁后,使用 weak_ptr 又成了一个未定义行为。unique_ptr不允许拷贝、赋值等操作,只能单一存在
std::shared_ptr<std::string> sps(new std::string);
std::shared_ptr<std::string> sps2(sps);
std::shared_ptr<int> spi(new int[100])
std::unique_ptr<std::string> ups(new std::string)手动分配、管理内存
使用 new 和 delete 关键字,即可完成对象的申请和销毁。但是这里有一个小小的问题,与我们之前所讲的东西有所不同的是,new 所返回的并不是如我们所想的 数组的指针,它直接返回的只是一个指针,我们在这个过程失去了数组的大小,而且你甚至不能判断它就是数组。
int* i = new int; // 创建一个 int 对象
int* is= new int[10]; // 创建一个 int[10] 对象
delete i; // 销毁一个 int 对象
delete [] is; // 销毁一个 int[10] 对象
int* pi = new int[0]; // 创建一个空对象
// 实际上这句话什么事情也没有做,pi 所指向的值是未定义的先分配内存空间,再进行初始化赋值
std::allocator
如果之前已经尝试过大量代码的同学,可能早就发现在使用STL的过程中,有一些报错的模板展开后,就有std::allocator类,
第 III 部分 类设计者的工具
第 13 章 拷贝控制
拷贝构造函数
Foo (); // 默认构造函数
Foo (const Foo&) // 拷贝构造函数合成拷贝构造函数,即默认的拷贝构造函数,会将源对象的所有内容拷贝到目标对象
std::string dots(10, '.'); // 直接初始化
std::string s(dots); // 直接初始化
std::string s2 = dots; // 拷贝初始化
std::string null_book = "9" // 拷贝初始化
std::string nines = std::string(100, '9')
// 拷贝初始化拷贝赋值函数
Foo& operator= (const Foo&); // 拷贝赋值同样的,拷贝复制也有合成拷贝赋值运算
移动构造函数
移动赋值运算符
析构函数
析构函数作为一种在对象生命周期结束的时候调用的一个函数,等同于给对象擦屁股的作用。于是,C++也提供了 RAII 等一系列功能。
生命周期如何结束:变量离开作用域,父级对象被销毁,容器被销毁,delete主动销毁,临时变量创建完整的表达式之后
C++ 三/五法则
当定义一个类时,我们显式地或隐式地指定了此类型的对象在拷贝、赋值和销毁时做什么。一个类通过定义三种特殊的成员函数来控制这些操作:拷贝构造函数、拷贝赋值运算符和析构函数。
拷贝构造函数定义了当用同类型的另一个对象初始化新对象时做什么,拷贝赋值运算符定义了将一个对象赋予同类型的另一个对象时做什么,析构函数定义了此类型的对象销毁时做什么。我们将这些操作称为拷贝控制操作。
由于拷贝控制操作是由三个特殊的成员函数来完成的,所以我们称此为“C++三法则”。在较新的 C++11 标准中,为了支持移动语义,
又增加了移动构造函数和移动赋值运算符,这样共有五个特殊的成员函数,所以又称为“C++五法则”。
也就是说,“三法则”是针对较旧的 C++89 标准说的,“五法则”是针对较新的 C++11 标准说的。
为了统一称呼,后来人们把它叫做“C++ 三/五法则”。
“需要析构函数的类也需要拷贝和赋值操作”
从“需要析构函数”可知,类中必然出现了指针类型的成员(否则不需要我们写析构函数,默认的析构函数就够了),所以,我们需要自己写析构函数来释放给指针所分配的内存来防止内存泄漏。
那么为什么说“也需要拷贝构造函数和赋值操作”呢?原因是:类中出现了指针类型的成员,必须防止浅拷贝问题。所以需要自己书写拷贝构造函数和拷贝赋值运算符,而不能使用默认的拷贝构造函数和默认的拷贝赋值运算符。
“需要拷贝操作的类也需要赋值操作,反之亦然”
“析构函数不能是删除的成员”
如果析构函数是删除的,那么无法销毁此类型的对象。对于一个删除了析构函数的类型,编译器不允许定义该类型的变量或创建该类的临时对象。而且,如果一个类有某个成员的类型删除了析构函数,我们也不能定义该类的变量或临时对象。
让编译器使用合成
class Foo {
public:
Foo () = default;
Foo (const Foo&) = default;
Foo& operator= (const Foo&);
~Foo () = default;
};
Foo& Foo::operator= (const Foo&) = default;阻止拷贝
如果要阻止拷贝,就把上面对应的default换成delete删除即可,但是delete必须出现在成员第一次声明的地方,即
class Foo {
public:
Foo () = default;
Foo (const Foo&) = default;
Foo& operator= (const Foo&) = delete;
~Foo () = default;
};其中,析构函数若被删除,我们就无法释放这些对象
如果一个类有数据成员不能默认构造、拷贝、复制或者销毁,则类对应的成员函数将被定义为删除。其原因是为了避免所创造的对象无法被销毁
但是这个功能是在c++11中引入的,在此之前,我们可以通过把对应的成员函数定义为private,外部的环境则无法访问对应的成员函数,实现了删除。声明但不定义是合法的,但是当使用这个函数时,会报链接错误,即找不到对应的函数定义,通过private声明,则可以阻止用户(我们)调用private函数,实现控制。
试着联系之前出现过的 std::unique_ptr 的禁止拷贝
尝试书写自己的资源管理类
值一样的类和指针一样的类,对应了之前的string类型和智能指针
动态内存管理类(std::allocator 续)
教你怎么实现 vector 类
申请一块内存区域,然后使用 allocator 复制内存区域到新申请的区域
对象移动和移动语义
为了避免在前面管理内存的时候,出现无意义的拷贝赋值,所以在c++11引入了右值引用,减少了对数据的拷贝,提升了效率
int i = 42;
int& ri = i; // 左值引用
int&& rri = i; // 编译错误,左值不能绑定到右值引用上
int& ri2 = 42 * i; // 编译错误,右值不能绑定到左值引用上
const int& cri = 42 * i; // 右值可以绑定到常量左值引用上
int&& rri2 = 42 * i; // 右值引用右值是临时的,而左值是永久的(在作用域内是永久的)
右值引用的好处是可以延长临时变量的生命周期。其基础上也实现了移动语言std::move和完美转发std::forward
能出现在等号左边的就是左值,右值只能出现在等号右边
使用移动操作时,要标明函数是不抛出异常的,否则会为此做一些额外的工作
class StrVec {
public:
StrVec (StrVec&&) noexcept;
};
StrVec::StrVec (StrVec&& s) noexcept : {
// ...
}引用限定符
class Foo {
public:
Foo& operator= (const Foo&) &; // 只能向可修改的左值赋值
};
Foo& Foo::operator= (const Foo& rhs) &;第 14 章 重载运算与类型转换
不可重载的运算符
大多数运算符都是可以重载的,但是有5个运算符C++语言规定是不可以重载的.
.(点运算符),通常用于去对象的成员,但是->(箭头运算符),是可以重载的::(域运算符),即类名+域运算符,取成员,不可以重载.*(点星运算符,)不可以重载,成员指针运算符".*,即成员是指针类型?:(条件运算符),不可以重载sizeof,不可以重载
C++ 只允许使用原本存在的运算符,而不支持自定义运算符,但是如果实现了这个功能,c++ 马上又起飞了
c++11 还引入了用户自定义字面量,似乎这个功能并没有在这本书中得以体现
long double operator"" pi(long double x) {
return x*3.14159265357;
}
long double operator"" pi(unsigned long long x) {
return static_cast<long double>(x)*3.14159265357;
}通过如上的代码我们可以实现自定义字面量,实现了xpi的数学写法,当然也可以给自然底数加上这样的功能
auto rad = 3pi;
auto rad2 = 4.0pi;c++20 其实还引入了一个新的运算符<=>三向比较运算符,俗称,飞碟运算符,这个就是后话了,这里也不赘述
重载运算符的使用
之前在一个群里听到有人吐槽 std::string 没有重载与部分类型的 + 运算,然后我就丢给了他这样子的代码
std::string operator+ (std::string str, int x) {
return str+std::to_string(x);
}
auto str = std::string ("H") + 123; // "H123"实现了 std::string 与 int 类型的直接相加
当然,上面相加的一行,也等价为
auto str = operator+ (std::string("H"), 123);
// 同理
auto i = operator+ (123, 321);
// 也是成立的,但是 operator 只能同时有两个参数,而且写起来也格外麻烦要注意的是,尽量不要使重载后的运算符的含义偏经离义,那会让使用者困惑。
又往下看了一些,发现 std::string 并没有把 + 作为自己的成员函数,而是当成了普通的非成员函数,所以也实现了 const char + std::string 的功能,如果是成员函数的话,const char 是不能放在前面的
输入输出运算符也是如此,应当作为非成员函数存在才能正常使用,不然以
ostream.>>(Foo) 的调用形式,是不能正确实现期望的功能的
ostream& operator<< (ostream& os, T t) {
// ...
}运算符介绍
算术运算符
无非就是加减乘除余和各种二元运算符
逻辑运算符
逻辑运算符和算术运算符使用方法基本一致
赋值运算符
普通的赋值运算符没有什么特别的,但是复合赋值运算符就有一些不同了,只传入一个参数,其中,左侧的被赋值对象的 this 指针会被传入
下标运算符
通常是返回访问元素的引用为好,此时可以多重下标运算
递增递减运算符
这里又有点小不同了,递增递减分为前置和后置,但是运算符重载总是以 operatorOPR的形式存在的,应当如何区分前置和后置呢?
int& operator++ (); // 前置
int& operator++ (int); // 后置后置递增运算符中,虽然出现了一个额外的参数,但是这个参数是不应当被使用到的,编译器为默认往里面传入0。此行为只是为了区分前后置
显式调用递增运算符
Foo p;
p.operator++(0); // 后置
p.operator++(); // 前置成员访问运算符
虽然我们不可以重载点成员访问运算符,但是我们可以重载箭头成员访问运算符
函数调用运算符
重载这个运算符,可以让我们的类对象表现得像函数一样
Foo foo;
foo(123); // 此处已然不是构造函数类型转换运算符
书中把这个内容放在了 lambda 的下面,但是我把它提了上来,放在了一起。类型转换函数一般形式如下:
operator type() const; // 显式类型转换运算符我们再一次联系之前所学到的内容,explicit
explicit type() const;只有当我们尝试使用显式类型转换时,才会调用这个函数
static_cast<type> a;书看到这里,也差不多能够解决我的一个疑问了,我当初就想,为什么一个流对象在循环中可以被当作条件使用,现在发现因为有隐式类型转换运算符重载的出现,所以在条件中,流被转换成一个bool类型的值返回,使循环可以正常运行
记得避免二义性转换
lambda 表达式再续前缘
cppreference 上面写道:lambda 就是创建一个闭包并返回,但是可能闭包这个概念解释起来也是过于复杂,所以 C++ primer 真的也只是做了一个 primer,从而不介绍具体的编程范式,这个大概可以在别的书中看到具体的操作方式。当然,网上也有很多类似的教程
c++ 是一个多范式编程语言,虽然在 lambda 出现之前就已经实现了函数式编程的功能,但是,lambda 表达式的存在,第一次让书写函数变得如此简练,写函数写起来真的是非常的爽快
于是乎,c++ 标准库为了符合的上自己的多范式编程语言的称号,也在 functional 中定义了一系列的函数式范式的类,用于生成对应的函数对象提供进一步的操作
| 算术 | 关系 | 逻辑 |
|---|---|---|
plus<T> |
equal_to<T> |
logical_and<T>| |
minus<T> |
not_equal_to<T> |
logical_or<T> |
multiplies<T> |
greater<T> |
logical_not<T> |
divides<T> |
greater_euql<T> |
|
modulus<T> |
less<T> |
|
negate<T> |
less_equal<T> |
可调用对象与function
今天下午,巨佬刚好怼着 std::function 喷了一堆,但是我也看不懂,他反驳的是 c++ 标准库中存在的那些糟粕,嫌弃 std::function 的性能之差,说
noexcept swap allocator等东西满天飞,到 2021 年还没有解决,自己写的ystdex::function 直接性能上都能把 libstdc++ 摁在地上锤除了实现难度比较大,而且吐槽了新议程中的试图把信号槽系统搬进标准c++的事情
当我们尝试做一个复杂的计算器时,会运用到非常多的计算功能,这些计算功能就是通过函数实现的,所以如何保存一个函数,就显得非常重要了,c++是一个静态语言,也不支持反射,所以不可能通过生成代码的方式生成一个函数,如果尝试诸如 lua、python 等语言的话,可以尝试一下这种方式
函数表
int add(int i, int j) { return i + j; }
auto mod = [] (int i, int j) -> int { return i + j; }
struct divide {
int operator() (int denominator, int divisor) {
return denominator / divisor;
}
}
std::map<std::string, int(*)(int,int)> binops;
binops.insert ({"+", add}); // 将 add 函数和 + 绑定在一起但是我们不能将 mod 和 divide 存入 binops,其中 lambda 有自己的类类型,与函数指针类型不匹配。解决办法是……std::function
std::function<int(int, int)> f1 = add;
std::function<int(int, int)> f2 = divide();
std::function<int(int, int)> f3 = [] (int i, int j) -> int { return i * j; };但是,std::function 会面临重载函数二义性的问题,因为赋值的时候只提供了一个关于函数的名字,但是没有任何参数,编译器无法推断此时应当使用哪一个函数存入 std::function
第 15 章 面向对象程序设计
面向对象的介绍
这个地方其实我自己也不知道应当如何介绍,只能抄一点书上的内容了
P525-576
面向对象的核心是数据抽象、继承和动态绑定
基类,派生类(也称为父类,子类)
派生类需要通过在类派生列表中明确指出它是从哪(些)个基类派生而得到的
虚函数使得派生类可以修改继承得到的那些标记为虚函数的函数,使之表现出不同的行为
动态绑定,运行时绑定,这个概念很奇怪,总之就是在代码运行的时候对不同的对象使用不同的成员函数
面向对象的使用
定义基类
virtual
override
定义派生类
阻止继承
final
虚函数
抽象基类:只含有纯虚函数的基类
访问控制
在之前第六章的时候我们讨论过一些访问控制,这里更加深入地去了解他们
public
protected
private
friend
其他类的操作
拷贝,赋值,移动,构造,析构……与先前的语法一致,但是可能会有一些不同
第 16 章 模板与泛型编程
定义一个模板
函数模板
template <typename T>
int compare (const T& v1, const T& v2) {
return v1<v2?-1:v2<v1?1:0;
}其实上面的代码实现了一个三相比较符,这个在c++20中以及被引入
我感觉如果接住了重载运算符的功能,就是用户自己添加运算符应当成为一个符合标准的事情才对
模板的特殊操作
template <unsigned N, unsigned M>
int compare (const char (&p1)[N], const char (&p2)[M]) {
return strcmp (p1, p2);
}往函数中传入了一个数组!!!
这都归功于模板的实例化,编译器在编译器就将数据的大小用我们看不到的方式传入了函数之中,让函数也直接得到了数组的大小
我们也可以使用 constexpr 对函数修饰要求能够在编译期返回一个常量结果
模板的保存总是又臭又长,因为其实例化展开的过程非常**,经常会让保存变得难以看懂,尤其是标准库那互相依赖一报上百个的报错
类模板
template <typename T>
class Foo {
};类模板其实和函数模板没有太大的区别,但是类模板需要手动指定类型实现实例化。类模板也存在偏特化和全特化,对视直接在类中写入对于什么样的类型执行什么样的操作。
比如 vector 和 map 创建一个对象的时候
在类外使用类模板名
template <typename T>
Foo<T> Foo<T>::operator+ (T a, T b) {
// ...
}一对一友元类,
通用和特定友好关系
令模板中的类型为自己的友元
模板类型别名
using strFoo = Foo<std::string>;static 成员
每一个实例化的类都有自己对应的静态成员
模板参数的作用域
使用类的类型成员
这里可以看看之前我们是如何声明容器的迭代器的,那样子我们对于模板类的类型成员也会有所感觉了
模板类的默认模板形参
template <class T = int>
class Foo {
// ...
}类成员函数模板
其实本质上和函数模板并无区别,无非就是身在类中
实例化与成员函数
实例化
控制实例化
extern template class Blob<string>;
template int compare (const int&, const int&);运行时绑定删除器
编译时绑定删除器
模板类型实参推断
类型转换与类型模板参数
template <typename T1, typename T2, typename T3>
T1 sum (T2, T3);
auto val3 = sum<long long>(i, lng);
// long long sum (int, long)尾置返回类型
标准库中的类型转换模板
函数指针和实参推断
模板实参推断和引用
主要是关于引用折叠和右值引用的参数相关的内容
理解 std::move
std::move 的定义
template <typename T>
typename remove_reference<T>::type&& move (T&& t) {
return static_cast<typename remove_reference<T>::type&&> (t);
}std::string s1("hi"), s2;
s2 = std::move (std::string ("HELLO"));
s2 = std::move (s1);从一个左值 static_cast 到一个右值是允许的
转发 std::forward
重载与模板
可变参数模板
模板参数包,函数参数包
我们使用一个省略号表示一个包,但是这个省略号实际上是由三个句号构成的,不是中文的省略号
使用 sizeof... 可以获取包的长度
template <typename T, typename... Args>
void foo (const T &t, const Args&... rest);编写可变参数函数模板
包扩展
c++11 中引入的包,使得解包可以较为方便地通过递归的方式实现
template <typename T, typename... Args>
ostream& print (ostream& os, const T& t, const Args&... rest) {
os << t << ",";
return print (os, rest...);
}转发参数包
模板特例化
第 IV 部分 高级主题
第 17 章 标准库特殊设施
认识 std::tuple
tuple 类似于 pairs,但是与 pairs 想不不同的是,pairs 只能存有两个(一对)类型,但是 tuple 可以存储若干个类型,所以这个类,在很多情况下也被用作函数返回值(与 struct 非常相近是不是?)
再会 std::bitset
其实 bitset 类,在这本书的开头我们就已经看到过了,现在是郑重其事地介绍一遍
可以理解为二进制数组,类似于java的bitmap吧,可以用来存储而静止图像
一个无限长度的整数类,也有支持的对应的运算符
初遇正则表达式
正则表达式才是真正的大头,这个功能真的是非常非常有用
头文件 regex
组件们
| 名称 | 介绍 |
|---|---|
| regex | 表示正则表达式的类 |
| regex_match | 进行正则匹配 |
| regex_search | 寻找第一个与表达式匹配的子序列 |
| regex_replace | 使用给定正则替换目标序列 |
| sregex_iterator | 调用regex_match匹配string中的所有匹配子序列 |
| smatch | 容器类,保存搜索结果 |
| ssub_match | string中匹配子表达式的结果 |
我们将在之后的时间里,详细地补充 regex 的使用方法,对于如何书写一个正则表达式,也会在届时详细补充
子表达式
随机数
在出现专门的随机数库之前,我们使用 cstdlib 提供的 rand 和 srand 生成随机数,但是 rand 返回的随机数结果是有范围,而且属于平均的随机,而且生成随机数的质量并不是很高,但是胜在速度足够快
随机数引擎
使用随机数引擎,我们甚至可以生成符合正态分布的随机数
再探 IO 库
我们讲了很多关于流的操作,但是我们没有将如何控制一个流。
但实际上,这个部分可以放弃了,在实际使用中,真的用的非常少,大家宁愿使用 printf, sprintf,也不会去使用 ostream 或者 stringstream 的格式化,因为真的是又臭又长,但是好处是处理效率很快,但是相比需要关心这个狗屁格式,显然是使用 c++20 引入的 format 库更加实用有效。
单字节操作
is.get, os.put, is.putback, is.unget, is.peek
多字节操作
is.get, is.getline, is.read, is.gcount, os.write, is.ignore
流随机访问
seek 和 tell 函数
第 18 章 用于大型程序的工具
异常处理
抛出异常
如何抛出一个异常其实还是一个非常富有技术含量的活
terminate 函数用于终止程序的运行,
如果代码写的足够多了,你经常可以发现自己的程序被杀死了,输出一条结果 xxx terminate: xxxx,大多数情况下是因为指针的问题,这个致命的异常要是一直没有被捕获,就会返回到最外层,然后调用 terminate 函数,终止程序的运行
捕获异常
noexcept
这个是不抛出异常,在我们之前使用 function 的时候也见到过
命名空间
命名空间的定义,使用,嵌套定义,分块定义,内联,无名,模板特例化,
调用命名空间内的成员
using 的使用
类、命名空间和作用域
多重继承和虚继承
第 19 章 特殊工具与技术
控制内存分配
当当,new 和 delete 相关的重载在这里出现了,我之前完全没有发现重载运算符那里没有讲new 和 delete,对了,delete 操作也是需要添加 noexcept 的修饰符的
c 中使用 malloc free 来分配释放内存,C++ 也继承了这部分功能
运行时类型识别(RTTI)
dynamic_cast
typeid 运算符,可以获取类型并返回 type_info
但是,其实 typeid 是一个非常慢的操作,我之前用这个玩意儿,还被大佬吐槽了一番,
枚举类型
C++11 引入了限定作用域的枚举类型,也让枚举拥有了更多的类型
枚举类型、联合体、结构体,这个在 c 中是作为一个基础的数据结构,在很早的时候就会被介绍到的,但是这里为了防止我们书写不那么 c++ 风格的代码,从而延后了。
限定枚举的作用域,在c中,枚举是在整个作用域可见的,导致枚举的名字不能重复,或者重复的意义可能出现不同,从而导致问题
使用 class 和 struct 表明枚举的范围
enum T { Tname1, Tname2, Tname3, Tname4 };
enum class CT { a, b, c, d };
Tname1 // ok
a // not ok
CT::a // ok我们还可以限定枚举中元素的类型,默认为 int,
enum class intValues : unsigned long long {
charTyp = 255, shortTyp = 65535, intTyp = 65535,
// 这里出现了一个非常有趣的事情,int 的上限居然和 short 一样
// 这个是因为标准没有明确规定int的具体长度,只规定了一个范围
longType = 4294967295UL, long_longType = 18446744073709551615ULL
};枚举类型的前置声明
enum class intValues : unsigned long long;枚举的形参匹配
只能是枚举,就算值和枚举一样,对应的还是枚举,而非这个值
类成员指针
数据成员指针
const std::string CLASS::* pdata;
// 指向 CLASS 对象的 std::string 成员 的 指针成员函数指针
char (CLASS::* pmf2) (CLASS::X, CLASS::y) const;
// 指针叫 pmf2,指向来自 CLASS 的函数
// 函数返回值为 char, 不能再函数内部修改变量的值
// 传入参数为 CLASS::X 和 CLASS::Y
using c = char (CLASS::*)(CLASS::X,CLASS::Y) const;
// 使用别名
c pmf3;成员指针函数表
将成员函数作为可调用对象
嵌套类
只是如此嵌套而已,似乎并没有什么可以多讲的
局部类
和嵌套类也很相似,但是没有什么特别的不同,我把它提前放置在这里
联合体:union
特殊的类,将多种数据结构在一个空间上存储,实现类型的动态变化
union 用于实现了 lua的动态类型
c++11更新之后,它就变成一种特殊的类,拥有了权限控制,默认都是 public
union UT{
char cval;
int ival;
long long llval;
double dval;
std::string sval;
};
std::map <std::string, UT> valueStack;同枚举,类,结构体一样,联合体是可以匿名的
我们可以使用枚举存储当前联合体中存储的类型,在进行操作时加以判断
C++ 的固有不可移植性
因为 c++ 为了高效,需要编译到机器码,机器码则与对应的硬件设施相关,而其调用的库则是平台相关,导致c++的移植总是需要重新编译一串代码
位域
volatile
volatile 要求编译器不要对这个变量以及相关的进行优化,因为在多线程下,如果某一段代码被优化了,另一个线程对其的修改其实就不能生效了,这就会导致一定的问题,具体的可以看到 https://www.zhihu.com/question/31459750/answer/52061391 。书中对其描写非常之少
extern "C"
让链接器使用其他语言的编译器编译其中的代码,但是得让这个代码和c++能够一起运行
附录 A 标准库
A.1 标准库名字和头文件
A.2 算法概览
find (beg, end, val)
find_if (beg, end, unaryPred)
find_if_not (beg, end, unaryPred)
count (beg, end, val)
count_if (beg, end, unaryPred)
all_of (beg, end, unaryPred)
any_of (beg, end, unaryPred)
none_of (beg, end, unaryPred)