《C++ Primer》5th 读书笔记
虽然说是这本书的笔记,但是还是会引入一些书外面的概念和新版标准的部分内容
对于不属于这本书的特殊的地方我会额外加以标注
[TOC]
第 1 章 开始
C++ 超级基础,
可以看我之前写的关于c++的必知必会的文章
UB(Undefined-Behaviors) 未定义行为
char 是 signed char 还是 unsigned char 是未定义的
int 是大于等于 short 小于等于 long 的
流
流可以作为 condition,用于判断是否到了流末尾,当到达流末尾时为 false,所以我们经常可以看到如下的写法
int n;
while (std::cin >> n) {
// do somthing...
}
此时调用了 std::cin 类的 >> 函数,往 n 中输入数据,返回的是 std::cin 类的 istream 对象,到达流末尾时(通常这个标记为 EOF(End-Of-File)),在windows上可通过 Ctrl-z 和 Ctrl-d 输入 EOF 符号,标志流结束。
>> 作为一个函数,同理
std::cout << "Hello World" << std::endl;
的 << 也是一个函数,但是你会发现,其中存在多次调用,因为 std::cout<< 的返回值是一个 ostream 对象,即 std::cout 本身,所以实现了上面这样子的连续调用,但实际上,这个操作可以像下面这样分解,
std::cout << "Hello World";
std::cout << std::endl;
这两种写法是完全等价的,于是就引出了一个问题,线程安全,因为,这个操作可以被等价分成两份,所以它的操作是不原子的,就可能在别的线程中,被插入,造成输出顺序混乱,比如输出了
Hello World123123\n
但是你想要输出的是
Hello World\n123123
其中,上面的\n的是转义字符,让换行看起来更加明显。解决办法也是有的,使用原子锁,但是这个内容是在后面学习多线程时才会讲到的,所以这里不加以赘述。
字面量
字面量大致可以分为两种,一种是语言提供的字面量,一种是库提供的字面量
语言提供的字面量,例如(其实我也没有仔细研究过具体哪些属于哪些,反正把自己知道的都列出来了)
// 指针字面量
nullptr;
// 布尔字面量
true;false;
// 整数字面量
auto a = 1; // int a
auto b = 0x1; // int b
auto c = 01; // int c
// 二进制字面量在 c++14 中引入
auto d = 0b1; // int d
auto e = 1u; // unsigned int e
auto f = 1ll; // long long f
auto uf= 1ull; // unsigned long long f
auto g = 1l; // long g
// 其实这些后缀大小写都是可以的,为了方便书写,这里都写小写
// 浮点数字面量
auto h = 1.0l; // long double h
auto i = 1e-1; // double i
auto j = 1.0f; // float j
auto k = 1e-1f; // float k
// 字符(串)字面量
auto l = "Hello"; // const char *l
auto m = u"World"; // const char16_t *m
auto n = U"你好"; // const char32_t *n
auto o = u8"世界"; // const char8_t *o
auto p = L'!'; // wchar_t p
auto q = '!'; // char q
但实际上,部分字面量会根据自己的数据大小自动变更数据类型,如果数据超过了long所能承载的范围,就会自动变为 long long,类型都是所能承受的最小类型,当然,char和short不在此列;
用户自定义字面量
使用运算符重载的方式
auto operator"" end(something) {
}
就可以弄一个 somethingend 的一个字面量,something 作为参数传入 函数,处理后返回
第 I 部分 C++ 基础
第 2 章 变量和基本类型
初始化与赋值
其实这个是老生常谈的问题了,因为总是有非常多的事情,在这个上面纠结
int a = 10; // mov DWORD PTR [rbp-4], 10
int b; //
int d = a; // mov eax, DWORD PTR [rbp-4]
// mov DWORD PTR [rbp-8], eax
int c = b; // mov eax, DWORD PTR [rbp-12]
// mov DWORD PTR [rbp-16], eax
b = 10; // mov DWORD PTR [rbp-12], 10
左侧为 c++ 代码,右侧为生成的汇编。这就很神奇了,你发现第二行定义变量 b 的时候,没有生成任何代码。在你尝试书写
int a = 10; // mov DWORD PTR [rbp-4], 10
int b; //
b = 10; // mov DWORD PTR [rbp-12], 10
如上的代码的时候,生成的汇编也只有两行,就算你开 -O0 也一样,因为这个定义的语句,的确,什么事情也没有干,只是告诉编译器,「这个位置我占掉了,虽然里面的东西我没有明确给它,但是我占了,你得让接下来的变量都往后挪挪,而且不能说我不在」的这种状态。
类型、限定符、修饰符
int, char, short, long, long long, float, double, long double 等被称为基础数据类型,一切的一切基于此而产生
分析一个变量的具体类型,应该从右王座看,看到 & 就是引用类型,看到 [] 就是数组类型,看到 *就是指针类型,然后看 顶层const还是底层const
人们喜欢讨论 * 这个字符用于限定变量的时候的位置,就会产生下面三种结果
int *p1; // *p1 的类型为 int
int * p1; // 两边各退一步
int* p1; // p1 的类型为 int*
我个人倾向于使用 int* 的方式,将其作为一整个类型,因为 c++ 的类型系统过于复杂,比如
int x = 20;
int* px = &x;
decltype(x) px2 = px;
如果说是 *p 的类型为 type 的话,应当如何解释 decltype(x) 所推断出来的类型?所以,我倾向于使用 type* name,auto px3 = px;也是如此,如果不是类型,何来「类型推断」?
同理,引用类型也是这样
// 指针
type* name1;
// 引用
(type*)& name2 = name1;
// 上面这个是对于指针类型的引用,引用必须要初始化
下面讲讲关于 const 和 constexpr
在此之前,真正的 constant 实际上是使用 #define 来定义的,但是 c++11 出现了 constexpr,终于可以用正经的方式定义一个真正的 constant 了。
constexpr 要求变量或者表达式的值能够在编译器得到计算,于是乎,用 constexpr 修饰的变量,是一个定值
const 所代表的是,不变量,与变量相对,只是在使用的过程中不会发生变化,但不代表它是一个固定的值
int a;
std::cin >> a;
const int b = a;
合法么,合法,但是 b 的值会随着我们的输入而发生变化,但是在接下来试图改变b的值,都会造成编译器错误。
但其实也不一定的,虽然说不能直接通过b修改b所对应的对象值,但是我们可以通过间接的方式,访问到b,并修改,而且不会引发编译器错误。
这个我们可以拿 nim 中类似的语句进行对比
const str = "Hello World"
# Mutable variables
var c: int
c = 20
# Immutable variables
let e = c
nim 中
const 是常量,var 是变量,let 是不可变量
c++ 中
constexpr 是常量,没有限定符的各种类型 是变量,const 是不可变量
这样一比其实也不难发现 c++ 在发展上的滞后性了
const int i = 20;
// 不能修改的 int 类型变量(不变量也是不会变的变量)
const int* const pi = &i;
// 首先,a 是 const,a 本身的值不能改动
// 其次,是 const int* 类型,代表是 cosnt int 类型的指针
// 说明 a 所指向的对象是 int 且不能修改
const int*& const rpi = pi;
// 一个 const int* 类型的引用,且本身也不能修改,(虽然说引用本来就不能改,不知道加上有没有
我们再加上一个数组类型,数组类型就非常有趣了,因为其中的矛盾点实在太多了,比如可以弱化成指针,这一点就很折磨人,所以和别人解释,但是这个内容再在下一章解释
自动类型推断
auto
decltype(statment)
decltype(auto) //c++17 引进
自定义数据结构,使用 struct 将各种数据归为一类,
但是好像没有看到 union 这个数据结构在这本书中被介绍
虽然说用的少,但其实,还是很有用的,比如用作动态类型的数据结构
第 3 章 字符串、向量和数组
其实这一章前面部分没有什么特别重要的事情,只不过介绍了 std::string 和 std::vector 两个标准库「容器」
我想这个内容可能看 C++ 标准库 可能更加适合一些
但有一点可以注意的就是
std::vector<std::string> a(10, "20");
std::vector<std::string> b{10, "20"};
的效果是一样的
迭代器
std::string::itrator;
std::vector<int>::itrator;
数组
int a[10];
using int10 = int[10];
int10 b;
第 4 章 表达式
提升,转换,重载,左右值
赋值,取址,解引用和下标……
都必须要使用左值,
decltype 对左值,取到的是一个引用,但对于右值,取到的是本来的类型
这个在之前的例子中有出现过
int i = 10;
int* pi = &i;
decltype (*pi) d = i; // 实际上这是 int& 类型
decltype (pi) e = pi; // 这个是 int* 类型
sizeof int
sizeof (1+1)
int a = f1() + f2();
像上面这两个函数返回值相加,但是你没有办法知道先执行的是哪一个函数,这个是不确定的,一定程度上也是线程不安全的
T operator+(const T &a, const T2 &b);
同理,因为加号会图上面这样子重载,对于某一个类型的重载,你也可以把int类型的+重载成*,这个以后再讲。f1和f2就成为了 operator+ 的两个参数,这样同样表明,函数作为函数参数时,其运行顺序也是不确定的
取余的运算比较复杂,日后重新罗列
第 5 章 语句
if
if-else
for
for
while
do-while
switch
break
continue
goto
throw
try
catch
第 6 章 函数
const 的故事到这里,才算真正地开始……
整个 c++11 就是一个类型斗争史,auto,decltype,template,using,透露出两个字,类型,类型,还是类型,函数重载、尾置返回、左值引用、右值引用也涉及到类型推断,
尾置返回类型
auto func (int i) -> int(*)[10];
函数参数中的顶层 const 会被忽略掉
void func (const int i);
void func (int i);
上面两个声明其实都是一个函数,会报错
void print (const int* i);
void print (const int i[]);
void print (const int i[10]);
上面三种声明,也是一样的,所以,在作为函数参数的时候,数组会弱化为指针
const int& i = 41;
void func (int& ar[]); // 引用的数组
void func (int (&ar)[]); // 数组的引用
函数返回数组指针
int (*function(void))[10]; // 一个返回指向 int[10] 的指针的函数
// 使用尾置返回
auto function(void) -> int(*)[10];
using pi10 = int(*)[10];
pi10 function (void);
函数返回函数指针
int (*function (void)) (int*, int);
auto function(void) -> int(*)(int*,int);
using ifpii = int(*)(int*, int);
ifpii function (void);
关于如何向数组传入长度参数,其实还有别的小妙招
template <typename T>
void func (int& ar[T]) {
}
type (*function(parameters))[dimension] {
}
可以定义一个返回 数组的指针 的函数
折叠表达式(C++17 起)
template<typename... Args>
bool all(Args... args) { return (... && args); }
template<typename... Args>
bool any(Args... args) { return (... || args); }
template<typename... Args>
bool sum(Args... args) { return (... + args); }
bool b = all(true, true, true, false);
// 在 all() 中,一元左折叠展开成
// return ((true && true) && true) && false;
// b 为 false
// 将一元折叠用于零长包展开时,仅允许下列运算符:
// 1) 逻辑与(&&)。空包的值为 true
// 2) 逻辑或(||)。空包的值为 false
// 3) 逗号运算符(,)。空包的值为 void()
// 注解
// 若用作 初值 或 形参包 的表达式在顶层具有优先级低于转型的运算符,则它可以加括号:
template<typename ...Args>
int sum(Args&&... args) {
// return (args + ... + 1 * 2); // 错误:优先级低于转型的运算符
return (args + ... + (1 * 2)); // OK
}
函数重载匹配其实也是一个很复杂的问题,
但是拒绝认识它也是可以的,就是不要写出具有歧义的重载函数
第 7 章 类
访问控制
public private protect
友元
friend
类成员
作用域和名字查找
构造函数初始化列表
委托构造函数
默认构造函数
=default =delete
隐式类类型转换
explicit
第 II 部分 C++ 标准库
第 8 章 IO 库

| 头文件 |
类型 |
描述 |
| iostream |
istream, wistream |
从流读入数据 |
| ostream, wostream |
向流写入数据 |
| iostream, wiostream |
读写流 |
| fstream |
ifstream, wifstream |
从文件流读入数据 |
| ofstream, wofstream |
向文件流写入数据 |
| fstream, wfstream |
文件读写流 |
| sstream |
istringstream, wistringstream |
从 string 读入数据 |
| ostringstream, wostringstream |
向 string 写入数据 |
| stringstream, wstringstream |
读写 string |
c++ 定义了上面这些流操作的类型,提供了最基础的流抽象功能,其他功能也可以基于此进行更深的抽象
但是,C++ 的流可能是一个非常失败的设计,因为输入输出的符号大家都不是很喜欢,而且在前期缺少合适的文本格式化工具,直到 c++20 引入了 format 库,才有所改观,但实际上现在没有任何一家的编译器是支持 format 库的再者是自带的 STL 库都没有提供对于标准化输入输出流的支持,只能自己手动输入输出。
但是我们也可以通过这个设计实现一个统一的输入输出操作
可以通过若干种标志判断当前流的状态处于失败、结尾、正常或者是异常
也可以通过对应的函数设置当前的状态
unitbuf, nounitbuf, flush, endl
立即刷新,不立即刷新,强制刷新,强制刷新并换行
我们可以使用 fstream 完成对文件流的读写操作,其具体操作与输入输出流并没有特别多的区别,唯一的是需要指明文件的路径和打开方式
需要注意的是,文件的写操作默认是附带 std::ios::trunc 的,这个意味着打开一个文件的时候,如果原先存在文件,则会将原先的文件删除
使用 stringstream 则可以对流进行细分,在实际使用中出现频率还是很高的
第 9 章 顺序容器
| 顺序容器主要有 |
类型 |
介绍 |
| vector |
动态数组,即长度可变,支持快速随机访问,数据连续存储,所以插入数据可能很慢 |
| deque |
双向队列,长度可变,支持快速随机访问,头尾插入删除很快,数据连续存储的同时分块存储 |
| list |
双向链表,长度可变,随机访问并不快速,任意一个元素的插入删除都很快,就链表的存储方式 |
| forward_list |
单向链表,长度可变,随机访问也不快速,但是相比双向链表少了一个方向,所以在插入和删除时比自己手写的链表快不了多少 |
| array |
静态数组,长度不可变,可以看作是原生数组的高级版本 |
| string |
和vector类似,但是专门用于保存字符,同时提供大量字符串处理相关的函数 |
| queue |
单向队列,由双向队列继承而来 |
| priority_queue |
| stack |
栈,由双向队列继承而来 |
其实这里有一个很巧妙的点,为什么说是快速随机访问呢,确实,链表因为数据结构的问题,其实不支持随机访问,但是可以通过遍历的方式,实现一个非常慢速的随机访问,但也其实,可以通过一个vector存储链表的迭代器,再对vector随机访问,就可以实现对链表的随机访问了,这个适用于大规模的对于链表的随机访问
同时,这些容器库之所以要叫容器库,是因为它们提供了对任意类型的「容」,这个得益于 c++ 复杂的模板,在编译器对各种类型进行展开,同时,由于模板的存在,很多本来看上去很正常的名字,就变得极为不正常了,这也导致使用了模板的报错变得异常难读,学会从模板报错中找到正确的错误,也是一个非常重要的技巧
这些容器库,STL,都包含着若干统一的操作函数,但这里就不一一列举了,这不应该成为学习 c++ 的负担。诸如比较,构造,复制,交换,添加删除,以及各类迭代器(c++11 引入了一种新的反迭代器,还有各种容器的构造,赋值,交换,追加,插入,删除,移动,拷贝,这里也不加以细说。
往容器中添加元素又变得非常有复杂,但也没有那么复杂
push_back, push_front, emplace_back, emplace_front, insert,其中 emplace 系列函数于 c++11 引入,究其原因还是因为 c++11 带来的右值引用,push 系列函数在插入一个值的时候,会先对值进行拷贝,但是 emplcae 函数借用右值引用直接将值写入对应位置,减少了一次拷贝,一定程度上提升了性能(右值引用牛逼!)
https://zhuanlan.zhihu.com/p/213853588
pop_back, pop_front, erase 用于删除元素
各个迭代器的使用,forward_list独树一帜的特殊操作
对于容器的插入删除可能导致迭代器失效,因为移动了容器中实际内容的位置,vector在内容将要填满预先分配的空间时,会将当前空间扩大为两倍,使用capacity可以查看已分配的空间,size查看已使用的空间
对字符串的各种操作函数在这里也不加以赘述了,实际上字符串库应当搭配c++11引入的regex正则匹配库和c++20引入的format格式化库使用更加顺手,正则匹配是一个好东西,就是看起来效率非常差,但也没有那么差了
第 10 章 泛型算法
泛型,何为泛型,即通用的,对于任何类型都可以使用,类型无关
这些泛型函数主要通过迭代器和传入的函数进行使用
其中大多数函数定义在 algorithm 算法库中,c++11 提供了超过一百种的内置算法,为开发提供了非常有用的帮助,尤其是 sort 函数我使用的次数不可谓不多
find, find_if...
(我会在将来的某天详细地介标准库的内容,但不会是在这本书上
泛型算法主要分为只读算法,写算法和排序算法
查找算法,判断算法等算法为只读算法
写算法,插入算法(使用插入迭代器),拷贝算法(利用迭代器),
排序算法,sort不稳定排序,stable_sort稳定排序,性能上各有千秋
之后,这本书在这个地方介绍了一个非常重量的 c++11 更新,lambda 函数,同时,这也更一步的让c++拥有了函数式编程的风范,一个较为简单的方式声明并使用一个函数,其中的详细内容我会另开一个文章进行介绍,但书中没有在这里引入function函数用来存储lambda函数我感觉还是有些欠妥当,不过也介绍了bind函数关于绑定函数参数的内容,同时介绍了find_if 函数和for_each 函数。值捕获,引用捕获,隐式捕获,等等等等,设置返回值,自动推断返回值,这里甚至还产生了闭包,但是在这本书里貌似没有介绍到。在lua中,闭包是一个非常重要的概念,而且在介绍lua的书中大书特书了
这里详细介绍了插入迭代器和反迭代器
第 11 章 关联容器
1)set or map 2)可否重复 3)有无顺序
因此产生了八种不同的数据类型,分别是:set map multiset multimap unordered_map unordered_set unordered_multimap unordered_multiset
因为map存储了两个信息,这里还引入了一个新的对象 pair,用于构成一对的数据结构,分别存储 map的key和value。关联容器同样拥有普通容器的大部分操作。之所以叫做关联,是因为key之间是相互影响的。比如在map和set中,是不允许出现相同的key的,这叫关联。
关联容器可以使用任意类型当作key和value,总之非常有用,但是具体的操作并不在这里赘述。一个非常有用的地方,就是统计单词的数量和有多少种单词,map的key为单数,value为数量,即可进行统计。set的key为单词,即可统计单词的种类,因为set在数学上与集合的含义相类似,所以在这里其实对于set还有非常多的集合操作,这本书上也没有讲。
然后我也没什么好讲的了,毕竟关于标准库的介绍不应该成为负担
第 12 章 动态内存
从程序支持手动申请内存开始,人类就陷入了无限的与指针的抗争之中。人们为了正确处理这些内存,掉了数不清的头发。所有分配的对象,需要一个能够指向它们的指针才能调用。手动分配的对象不受作用域或者生命周期影响。但是用来存储这个指针的对象,存在作用域和生命周期,当语句块结束后,这个指针变量则会消失,也许指针变成返回值传到另一个变量之中,也许没有。如果没有的话,那么这个内存中的对象就彻底变得无主了,于是这个内存中的对象就无法已正常地形式进行清除了。
这就形成了垃圾,于是我们引入了垃圾回收的概念,这个在相当多的语言中都有直接的体会,但是,这么方便为什么c++不用呢?因为垃圾回收,浪费空间,也浪费性能,所以这个功能不会在c++中提供,诸如python和lua,会对一些垃圾自动「标记-清理」。如果尝试写python,循环地进行一些事项,你有可能发现自己的内存占用,忽高忽低,这个就是python垃圾回收的效果了。
智能指针
但是c++难道没有办法高效地实现垃圾回收了么?当然是有的。答案就是使用智能指针,智能指针是在C++11中引入的。既然问题出现在指针上,那么解决这个指针,那么所有的问题就迎刃而解了。借助 c++ 类所带来的 RAII 功能,我们可以轻松实现,创建时如何,销毁时如何的功能。这也为智能指针的出现,奠定了基础。
智能指针分为三类
shared_ptr
unique_ptr
weak_ptr
其中,shared_ptr可以被赋值,拷贝,即可以存在多份,每次赋值拷贝会调用对应的构造函数,返回这样一个指针也会产生拷贝。每一次执行上述的操作时,其内部的计数器,会让自己的值增加一,只要内部计数器的值达到零,就会自动销毁内存中的对象。当然,这个时候,智能指针对象也肯定不会存在的。其中,weak_ptr是不会增长这个计数器,但是,当目标对象被销毁后,使用 weak_ptr 又成了一个未定义行为。unique_ptr不允许拷贝、赋值等操作,只能单一存在
std::shared_ptr<std::string> sps(new std::string);
std::shared_ptr<std::string> sps2(sps);
std::shared_ptr<int> spi(new int[100])
std::unique_ptr<std::string> ups(new std::string)
手动分配、管理内存
使用 new 和 delete 关键字,即可完成对象的申请和销毁。但是这里有一个小小的问题,与我们之前所讲的东西有所不同的是,new 所返回的并不是如我们所想的 数组的指针,它直接返回的只是一个指针,我们在这个过程失去了数组的大小,而且你甚至不能判断它就是数组。
int* i = new int; // 创建一个 int 对象
int* is= new int[10]; // 创建一个 int[10] 对象
delete i; // 销毁一个 int 对象
delete [] is; // 销毁一个 int[10] 对象
int* pi = new int[0]; // 创建一个空对象
// 实际上这句话什么事情也没有做,pi 所指向的值是未定义的
先分配内存空间,再进行初始化赋值
std::allocator
如果之前已经尝试过大量代码的同学,可能早就发现在使用STL的过程中,有一些报错的模板展开后,就有std::allocator类,
第 III 部分 类设计者的工具
第 13 章 拷贝控制
拷贝构造函数
Foo (); // 默认构造函数
Foo (const Foo&) // 拷贝构造函数
合成拷贝构造函数,即默认的拷贝构造函数,会将源对象的所有内容拷贝到目标对象
std::string dots(10, '.'); // 直接初始化
std::string s(dots); // 直接初始化
std::string s2 = dots; // 拷贝初始化
std::string null_book = "9" // 拷贝初始化
std::string nines = std::string(100, '9')
// 拷贝初始化
拷贝赋值函数
Foo& operator= (const Foo&); // 拷贝赋值
同样的,拷贝复制也有合成拷贝赋值运算
移动构造函数
移动赋值运算符
析构函数
析构函数作为一种在对象生命周期结束的时候调用的一个函数,等同于给对象擦屁股的作用。于是,C++也提供了 RAII 等一系列功能。
生命周期如何结束:变量离开作用域,父级对象被销毁,容器被销毁,delete主动销毁,临时变量创建完整的表达式之后
C++ 三/五法则
当定义一个类时,我们显式地或隐式地指定了此类型的对象在拷贝、赋值和销毁时做什么。一个类通过定义三种特殊的成员函数来控制这些操作:拷贝构造函数、拷贝赋值运算符和析构函数。
拷贝构造函数定义了当用同类型的另一个对象初始化新对象时做什么,拷贝赋值运算符定义了将一个对象赋予同类型的另一个对象时做什么,析构函数定义了此类型的对象销毁时做什么。我们将这些操作称为拷贝控制操作。
由于拷贝控制操作是由三个特殊的成员函数来完成的,所以我们称此为“C++三法则”。在较新的 C++11 标准中,为了支持移动语义,
又增加了移动构造函数和移动赋值运算符,这样共有五个特殊的成员函数,所以又称为“C++五法则”。
也就是说,“三法则”是针对较旧的 C++89 标准说的,“五法则”是针对较新的 C++11 标准说的。
为了统一称呼,后来人们把它叫做“C++ 三/五法则”。
“需要析构函数的类也需要拷贝和赋值操作”
从“需要析构函数”可知,类中必然出现了指针类型的成员(否则不需要我们写析构函数,默认的析构函数就够了),所以,我们需要自己写析构函数来释放给指针所分配的内存来防止内存泄漏。
那么为什么说“也需要拷贝构造函数和赋值操作”呢?原因是:类中出现了指针类型的成员,必须防止浅拷贝问题。所以需要自己书写拷贝构造函数和拷贝赋值运算符,而不能使用默认的拷贝构造函数和默认的拷贝赋值运算符。
“需要拷贝操作的类也需要赋值操作,反之亦然”
“析构函数不能是删除的成员”
如果析构函数是删除的,那么无法销毁此类型的对象。对于一个删除了析构函数的类型,编译器不允许定义该类型的变量或创建该类的临时对象。而且,如果一个类有某个成员的类型删除了析构函数,我们也不能定义该类的变量或临时对象。
让编译器使用合成
class Foo {
public:
Foo () = default;
Foo (const Foo&) = default;
Foo& operator= (const Foo&);
~Foo () = default;
};
Foo& Foo::operator= (const Foo&) = default;
阻止拷贝
如果要阻止拷贝,就把上面对应的default换成delete删除即可,但是delete必须出现在成员第一次声明的地方,即
class Foo {
public:
Foo () = default;
Foo (const Foo&) = default;
Foo& operator= (const Foo&) = delete;
~Foo () = default;
};
其中,析构函数若被删除,我们就无法释放这些对象
如果一个类有数据成员不能默认构造、拷贝、复制或者销毁,则类对应的成员函数将被定义为删除。其原因是为了避免所创造的对象无法被销毁
但是这个功能是在c++11中引入的,在此之前,我们可以通过把对应的成员函数定义为private,外部的环境则无法访问对应的成员函数,实现了删除。声明但不定义是合法的,但是当使用这个函数时,会报链接错误,即找不到对应的函数定义,通过private声明,则可以阻止用户(我们)调用private函数,实现控制。
试着联系之前出现过的 std::unique_ptr 的禁止拷贝
尝试书写自己的资源管理类
值一样的类和指针一样的类,对应了之前的string类型和智能指针
动态内存管理类(std::allocator 续)
教你怎么实现 vector 类
申请一块内存区域,然后使用 allocator 复制内存区域到新申请的区域
对象移动和移动语义
为了避免在前面管理内存的时候,出现无意义的拷贝赋值,所以在c++11引入了右值引用,减少了对数据的拷贝,提升了效率
int i = 42;
int& ri = i; // 左值引用
int&& rri = i; // 编译错误,左值不能绑定到右值引用上
int& ri2 = 42 * i; // 编译错误,右值不能绑定到左值引用上
const int& cri = 42 * i; // 右值可以绑定到常量左值引用上
int&& rri2 = 42 * i; // 右值引用
右值是临时的,而左值是永久的(在作用域内是永久的)
右值引用的好处是可以延长临时变量的生命周期。其基础上也实现了移动语言std::move和完美转发std::forward
能出现在等号左边的就是左值,右值只能出现在等号右边
使用移动操作时,要标明函数是不抛出异常的,否则会为此做一些额外的工作
class StrVec {
public:
StrVec (StrVec&&) noexcept;
};
StrVec::StrVec (StrVec&& s) noexcept : {
// ...
}
引用限定符
class Foo {
public:
Foo& operator= (const Foo&) &; // 只能向可修改的左值赋值
};
Foo& Foo::operator= (const Foo& rhs) &;
第 14 章 重载运算与类型转换
不可重载的运算符
大多数运算符都是可以重载的,但是有5个运算符C++语言规定是不可以重载的.
.(点运算符),通常用于去对象的成员,但是->(箭头运算符),是可以重载的::(域运算符),即类名+域运算符,取成员,不可以重载.*(点星运算符,)不可以重载,成员指针运算符".*,即成员是指针类型?:(条件运算符),不可以重载sizeof,不可以重载
C++ 只允许使用原本存在的运算符,而不支持自定义运算符,但是如果实现了这个功能,c++ 马上又起飞了
c++11 还引入了用户自定义字面量,似乎这个功能并没有在这本书中得以体现
long double operator"" pi(long double x) {
return x*3.14159265357;
}
long double operator"" pi(unsigned long long x) {
return static_cast<long double>(x)*3.14159265357;
}
通过如上的代码我们可以实现自定义字面量,实现了xpi的数学写法,当然也可以给自然底数加上这样的功能
auto rad = 3pi;
auto rad2 = 4.0pi;
c++20 其实还引入了一个新的运算符<=>三向比较运算符,俗称,飞碟运算符,这个就是后话了,这里也不赘述
重载运算符的使用
之前在一个群里听到有人吐槽 std::string 没有重载与部分类型的 + 运算,然后我就丢给了他这样子的代码
std::string operator+ (std::string str, int x) {
return str+std::to_string(x);
}
auto str = std::string ("H") + 123; // "H123"
实现了 std::string 与 int 类型的直接相加
当然,上面相加的一行,也等价为
auto str = operator+ (std::string("H"), 123);
// 同理
auto i = operator+ (123, 321);
// 也是成立的,但是 operator 只能同时有两个参数,而且写起来也格外麻烦
要注意的是,尽量不要使重载后的运算符的含义偏经离义,那会让使用者困惑。
又往下看了一些,发现 std::string 并没有把 + 作为自己的成员函数,而是当成了普通的非成员函数,所以也实现了 const char + std::string 的功能,如果是成员函数的话,const char 是不能放在前面的
输入输出运算符也是如此,应当作为非成员函数存在才能正常使用,不然以
ostream.>>(Foo) 的调用形式,是不能正确实现期望的功能的
ostream& operator<< (ostream& os, T t) {
// ...
}
运算符介绍
算术运算符
无非就是加减乘除余和各种二元运算符
逻辑运算符
逻辑运算符和算术运算符使用方法基本一致
赋值运算符
普通的赋值运算符没有什么特别的,但是复合赋值运算符就有一些不同了,只传入一个参数,其中,左侧的被赋值对象的 this 指针会被传入
下标运算符
通常是返回访问元素的引用为好,此时可以多重下标运算
递增递减运算符
这里又有点小不同了,递增递减分为前置和后置,但是运算符重载总是以 operatorOPR的形式存在的,应当如何区分前置和后置呢?
int& operator++ (); // 前置
int& operator++ (int); // 后置
后置递增运算符中,虽然出现了一个额外的参数,但是这个参数是不应当被使用到的,编译器为默认往里面传入0。此行为只是为了区分前后置
显式调用递增运算符
Foo p;
p.operator++(0); // 后置
p.operator++(); // 前置
成员访问运算符
虽然我们不可以重载点成员访问运算符,但是我们可以重载箭头成员访问运算符
函数调用运算符
重载这个运算符,可以让我们的类对象表现得像函数一样
Foo foo;
foo(123); // 此处已然不是构造函数
类型转换运算符
书中把这个内容放在了 lambda 的下面,但是我把它提了上来,放在了一起。类型转换函数一般形式如下:
operator type() const; // 显式类型转换运算符
我们再一次联系之前所学到的内容,explicit
explicit type() const;
只有当我们尝试使用显式类型转换时,才会调用这个函数
static_cast<type> a;
书看到这里,也差不多能够解决我的一个疑问了,我当初就想,为什么一个流对象在循环中可以被当作条件使用,现在发现因为有隐式类型转换运算符重载的出现,所以在条件中,流被转换成一个bool类型的值返回,使循环可以正常运行
记得避免二义性转换
lambda 表达式再续前缘
cppreference 上面写道:lambda 就是创建一个闭包并返回,但是可能闭包这个概念解释起来也是过于复杂,所以 C++ primer 真的也只是做了一个 primer,从而不介绍具体的编程范式,这个大概可以在别的书中看到具体的操作方式。当然,网上也有很多类似的教程
c++ 是一个多范式编程语言,虽然在 lambda 出现之前就已经实现了函数式编程的功能,但是,lambda 表达式的存在,第一次让书写函数变得如此简练,写函数写起来真的是非常的爽快
于是乎,c++ 标准库为了符合的上自己的多范式编程语言的称号,也在 functional 中定义了一系列的函数式范式的类,用于生成对应的函数对象提供进一步的操作
| 算术 |
关系 |
逻辑 |
plus<T> |
equal_to<T> |
logical_and<T>| |
minus<T> |
not_equal_to<T> |
logical_or<T> |
multiplies<T> |
greater<T> |
logical_not<T> |
divides<T> |
greater_euql<T> |
modulus<T> |
less<T> |
negate<T> |
less_equal<T> |
可调用对象与function
今天下午,巨佬刚好怼着 std::function 喷了一堆,但是我也看不懂,他反驳的是 c++ 标准库中存在的那些糟粕,嫌弃 std::function 的性能之差,说 noexcept swap allocator 等东西满天飞,到 2021 年还没有解决,自己写的 ystdex::function 直接性能上都能把 libstdc++ 摁在地上锤 除了实现难度比较大,而且吐槽了新议程中的试图把信号槽系统搬进标准c++的事情
当我们尝试做一个复杂的计算器时,会运用到非常多的计算功能,这些计算功能就是通过函数实现的,所以如何保存一个函数,就显得非常重要了,c++是一个静态语言,也不支持反射,所以不可能通过生成代码的方式生成一个函数,如果尝试诸如 lua、python 等语言的话,可以尝试一下这种方式
函数表
int add(int i, int j) { return i + j; }
auto mod = [] (int i, int j) -> int { return i + j; }
struct divide {
int operator() (int denominator, int divisor) {
return denominator / divisor;
}
}
std::map<std::string, int(*)(int,int)> binops;
binops.insert ({"+", add}); // 将 add 函数和 + 绑定在一起
但是我们不能将 mod 和 divide 存入 binops,其中 lambda 有自己的类类型,与函数指针类型不匹配。解决办法是……std::function
std::function<int(int, int)> f1 = add;
std::function<int(int, int)> f2 = divide();
std::function<int(int, int)> f3 = [] (int i, int j) -> int { return i * j; };
但是,std::function 会面临重载函数二义性的问题,因为赋值的时候只提供了一个关于函数的名字,但是没有任何参数,编译器无法推断此时应当使用哪一个函数存入 std::function
第 15 章 面向对象程序设计
面向对象的介绍
这个地方其实我自己也不知道应当如何介绍,只能抄一点书上的内容了
P525-576
面向对象的核心是数据抽象、继承和动态绑定
基类,派生类(也称为父类,子类)
派生类需要通过在类派生列表中明确指出它是从哪(些)个基类派生而得到的
虚函数使得派生类可以修改继承得到的那些标记为虚函数的函数,使之表现出不同的行为
动态绑定,运行时绑定,这个概念很奇怪,总之就是在代码运行的时候对不同的对象使用不同的成员函数
面向对象的使用
定义基类
virtual
override
定义派生类
阻止继承
final
虚函数
抽象基类:只含有纯虚函数的基类
访问控制
在之前第六章的时候我们讨论过一些访问控制,这里更加深入地去了解他们
public
protected
private
friend
其他类的操作
拷贝,赋值,移动,构造,析构……与先前的语法一致,但是可能会有一些不同
第 16 章 模板与泛型编程
定义一个模板
函数模板
template <typename T>
int compare (const T& v1, const T& v2) {
return v1<v2?-1:v2<v1?1:0;
}
其实上面的代码实现了一个三相比较符,这个在c++20中以及被引入
我感觉如果接住了重载运算符的功能,就是用户自己添加运算符应当成为一个符合标准的事情才对
模板的特殊操作
template <unsigned N, unsigned M>
int compare (const char (&p1)[N], const char (&p2)[M]) {
return strcmp (p1, p2);
}
往函数中传入了一个数组!!!
这都归功于模板的实例化,编译器在编译器就将数据的大小用我们看不到的方式传入了函数之中,让函数也直接得到了数组的大小
我们也可以使用 constexpr 对函数修饰要求能够在编译期返回一个常量结果
模板的保存总是又臭又长,因为其实例化展开的过程非常**,经常会让保存变得难以看懂,尤其是标准库那互相依赖一报上百个的报错
类模板
template <typename T>
class Foo {
};
类模板其实和函数模板没有太大的区别,但是类模板需要手动指定类型实现实例化。类模板也存在偏特化和全特化,对视直接在类中写入对于什么样的类型执行什么样的操作。
比如 vector 和 map 创建一个对象的时候
在类外使用类模板名
template <typename T>
Foo<T> Foo<T>::operator+ (T a, T b) {
// ...
}
一对一友元类,
通用和特定友好关系
令模板中的类型为自己的友元
模板类型别名
using strFoo = Foo<std::string>;
static 成员
每一个实例化的类都有自己对应的静态成员
模板参数的作用域
使用类的类型成员
这里可以看看之前我们是如何声明容器的迭代器的,那样子我们对于模板类的类型成员也会有所感觉了
模板类的默认模板形参
template <class T = int>
class Foo {
// ...
}
类成员函数模板
其实本质上和函数模板并无区别,无非就是身在类中
实例化与成员函数
实例化
控制实例化
extern template class Blob<string>;
template int compare (const int&, const int&);
运行时绑定删除器
编译时绑定删除器
模板类型实参推断
类型转换与类型模板参数
template <typename T1, typename T2, typename T3>
T1 sum (T2, T3);
auto val3 = sum<long long>(i, lng);
// long long sum (int, long)
尾置返回类型
标准库中的类型转换模板
函数指针和实参推断
模板实参推断和引用
主要是关于引用折叠和右值引用的参数相关的内容
理解 std::move
std::move 的定义
template <typename T>
typename remove_reference<T>::type&& move (T&& t) {
return static_cast<typename remove_reference<T>::type&&> (t);
}
std::string s1("hi"), s2;
s2 = std::move (std::string ("HELLO"));
s2 = std::move (s1);
从一个左值 static_cast 到一个右值是允许的
转发 std::forward
重载与模板
可变参数模板
模板参数包,函数参数包
我们使用一个省略号表示一个包,但是这个省略号实际上是由三个句号构成的,不是中文的省略号
使用 sizeof... 可以获取包的长度
template <typename T, typename... Args>
void foo (const T &t, const Args&... rest);
编写可变参数函数模板
包扩展
c++11 中引入的包,使得解包可以较为方便地通过递归的方式实现
template <typename T, typename... Args>
ostream& print (ostream& os, const T& t, const Args&... rest) {
os << t << ",";
return print (os, rest...);
}
转发参数包
模板特例化
第 IV 部分 高级主题
第 17 章 标准库特殊设施
认识 std::tuple
tuple 类似于 pairs,但是与 pairs 想不不同的是,pairs 只能存有两个(一对)类型,但是 tuple 可以存储若干个类型,所以这个类,在很多情况下也被用作函数返回值(与 struct 非常相近是不是?)
再会 std::bitset
其实 bitset 类,在这本书的开头我们就已经看到过了,现在是郑重其事地介绍一遍
可以理解为二进制数组,类似于java的bitmap吧,可以用来存储而静止图像
一个无限长度的整数类,也有支持的对应的运算符
初遇正则表达式
正则表达式才是真正的大头,这个功能真的是非常非常有用
头文件 regex
组件们
| 名称 |
介绍 |
| regex |
表示正则表达式的类 |
| regex_match |
进行正则匹配 |
| regex_search |
寻找第一个与表达式匹配的子序列 |
| regex_replace |
使用给定正则替换目标序列 |
| sregex_iterator |
调用regex_match匹配string中的所有匹配子序列 |
| smatch |
容器类,保存搜索结果 |
| ssub_match |
string中匹配子表达式的结果 |
我们将在之后的时间里,详细地补充 regex 的使用方法,对于如何书写一个正则表达式,也会在届时详细补充
子表达式
随机数
在出现专门的随机数库之前,我们使用 cstdlib 提供的 rand 和 srand 生成随机数,但是 rand 返回的随机数结果是有范围,而且属于平均的随机,而且生成随机数的质量并不是很高,但是胜在速度足够快
随机数引擎
使用随机数引擎,我们甚至可以生成符合正态分布的随机数
再探 IO 库
我们讲了很多关于流的操作,但是我们没有将如何控制一个流。
但实际上,这个部分可以放弃了,在实际使用中,真的用的非常少,大家宁愿使用 printf, sprintf,也不会去使用 ostream 或者 stringstream 的格式化,因为真的是又臭又长,但是好处是处理效率很快,但是相比需要关心这个狗屁格式,显然是使用 c++20 引入的 format 库更加实用有效。
单字节操作
is.get, os.put, is.putback, is.unget, is.peek
多字节操作
is.get, is.getline, is.read, is.gcount, os.write, is.ignore
流随机访问
seek 和 tell 函数
第 18 章 用于大型程序的工具
异常处理
抛出异常
如何抛出一个异常其实还是一个非常富有技术含量的活
terminate 函数用于终止程序的运行,
如果代码写的足够多了,你经常可以发现自己的程序被杀死了,输出一条结果 xxx terminate: xxxx,大多数情况下是因为指针的问题,这个致命的异常要是一直没有被捕获,就会返回到最外层,然后调用 terminate 函数,终止程序的运行
捕获异常
noexcept
这个是不抛出异常,在我们之前使用 function 的时候也见到过
命名空间
命名空间的定义,使用,嵌套定义,分块定义,内联,无名,模板特例化,
调用命名空间内的成员
using 的使用
类、命名空间和作用域
多重继承和虚继承
第 19 章 特殊工具与技术
控制内存分配
当当,new 和 delete 相关的重载在这里出现了,我之前完全没有发现重载运算符那里没有讲new 和 delete,对了,delete 操作也是需要添加 noexcept 的修饰符的
c 中使用 malloc free 来分配释放内存,C++ 也继承了这部分功能
运行时类型识别(RTTI)
dynamic_cast
typeid 运算符,可以获取类型并返回 type_info
但是,其实 typeid 是一个非常慢的操作,我之前用这个玩意儿,还被大佬吐槽了一番,
枚举类型
C++11 引入了限定作用域的枚举类型,也让枚举拥有了更多的类型
枚举类型、联合体、结构体,这个在 c 中是作为一个基础的数据结构,在很早的时候就会被介绍到的,但是这里为了防止我们书写不那么 c++ 风格的代码,从而延后了。
限定枚举的作用域,在c中,枚举是在整个作用域可见的,导致枚举的名字不能重复,或者重复的意义可能出现不同,从而导致问题
使用 class 和 struct 表明枚举的范围
enum T { Tname1, Tname2, Tname3, Tname4 };
enum class CT { a, b, c, d };
Tname1 // ok
a // not ok
CT::a // ok
我们还可以限定枚举中元素的类型,默认为 int,
enum class intValues : unsigned long long {
charTyp = 255, shortTyp = 65535, intTyp = 65535,
// 这里出现了一个非常有趣的事情,int 的上限居然和 short 一样
// 这个是因为标准没有明确规定int的具体长度,只规定了一个范围
longType = 4294967295UL, long_longType = 18446744073709551615ULL
};
枚举类型的前置声明
enum class intValues : unsigned long long;
枚举的形参匹配
只能是枚举,就算值和枚举一样,对应的还是枚举,而非这个值
类成员指针
数据成员指针
const std::string CLASS::* pdata;
// 指向 CLASS 对象的 std::string 成员 的 指针
成员函数指针
char (CLASS::* pmf2) (CLASS::X, CLASS::y) const;
// 指针叫 pmf2,指向来自 CLASS 的函数
// 函数返回值为 char, 不能再函数内部修改变量的值
// 传入参数为 CLASS::X 和 CLASS::Y
using c = char (CLASS::*)(CLASS::X,CLASS::Y) const;
// 使用别名
c pmf3;
成员指针函数表
将成员函数作为可调用对象
嵌套类
只是如此嵌套而已,似乎并没有什么可以多讲的
局部类
和嵌套类也很相似,但是没有什么特别的不同,我把它提前放置在这里
联合体:union
特殊的类,将多种数据结构在一个空间上存储,实现类型的动态变化
union 用于实现了 lua的动态类型
c++11更新之后,它就变成一种特殊的类,拥有了权限控制,默认都是 public
union UT{
char cval;
int ival;
long long llval;
double dval;
std::string sval;
};
std::map <std::string, UT> valueStack;
同枚举,类,结构体一样,联合体是可以匿名的
我们可以使用枚举存储当前联合体中存储的类型,在进行操作时加以判断
C++ 的固有不可移植性
因为 c++ 为了高效,需要编译到机器码,机器码则与对应的硬件设施相关,而其调用的库则是平台相关,导致c++的移植总是需要重新编译一串代码
位域
volatile
volatile 要求编译器不要对这个变量以及相关的进行优化,因为在多线程下,如果某一段代码被优化了,另一个线程对其的修改其实就不能生效了,这就会导致一定的问题,具体的可以看到 https://www.zhihu.com/question/31459750/answer/52061391 。书中对其描写非常之少
extern "C"
让链接器使用其他语言的编译器编译其中的代码,但是得让这个代码和c++能够一起运行
附录 A 标准库
A.1 标准库名字和头文件
A.2 算法概览
find (beg, end, val)
find_if (beg, end, unaryPred)
find_if_not (beg, end, unaryPred)
count (beg, end, val)
count_if (beg, end, unaryPred)
all_of (beg, end, unaryPred)
any_of (beg, end, unaryPred)
none_of (beg, end, unaryPred)
A.3 随机数
索引

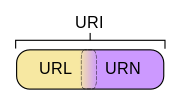 也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。
也就是说,URI分为三种,URL or URN or (URL and URI)URL代表资源的路径地址,而URI代表资源的名称。通过URL找到资源是对网络位置进行标识,如:http://example.org/absolute/URI/with/absolute/path/to/resource.txtftp://example.org/resource.txt通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:urn:issn:1535-3613编辑于 2016-03-09赞同 5213 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续姜贵Always59 人赞同了该回答原来uri包括url和urn,后来urn没流行起来,导致几乎目前所有的uri都是url发布于 2014-10-08赞同 592 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续封火星46 人赞同了该回答URI = Uniform Resource Identifier 统一资源标志符URL = Uniform Resource Locator 统一资源定位符URN = Uniform Resource Name 统一资源名称大白话,就是URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。编辑于 2019-11-11赞同 464 条评论分享收藏喜欢继续浏览内容知乎发现更大的世界打开Chrome继续西毒喜欢装逼,喜欢写代码,喜欢杜甫的诗。84 人赞同了该回答从鄙人程序员的角度理解,URI属于URL更高层次的抽象,一种字符串文本标准。就是说,URI属于父类,而URL属于URI的子类。URL是URI的一个子集。在《HTTP权威指南》一书中,对于URI的定义是:统一资源标识符;对于URL的定义是:统一资源定位符。二者的区别在于,URI表示请求服务器的路径,定义这么一个资源。而URL同时说明要如何访问这个资源(http://)。例如,一个URL通常包括三部分:方案部分(scheme):http://地址部分:CEALER | 一些瞬间、一些回忆、一些经典、一些原创、一些愤怒、一些感动资源部分:/1.png而在C#中,URL类属于System.Security.Policy命名空间,Uri属于System。在MSDN对Url类的备注中,能更好的说明Url与Uri的区别:Url 证据的存在将在授予集内生成 UrlIdentityPermission。如果有对 UrlIdentityPermission 的 Demand,则与 Url 证据对应的 UrlIdentityPermission 将与请求的权限进行比较。考虑完整的 URL,包括协议(HTTP、HTTPS、FTP)和文件。例如,Microsoft Home Page 就是一个完整的 URL。URL 可以精确匹配,也可在最后一个位置使用通配符来匹配。例如,Microsoft Home Page* 就是一个含通配符的 URL。而Uri类在实例化的时候,可以指定为绝对路径,相对路径,但可以不指定到具体的某个资源。那么我理解的二者的区别就是:URI可以表示一个域,也可以表示一个资源。URL只能表示一个资源。 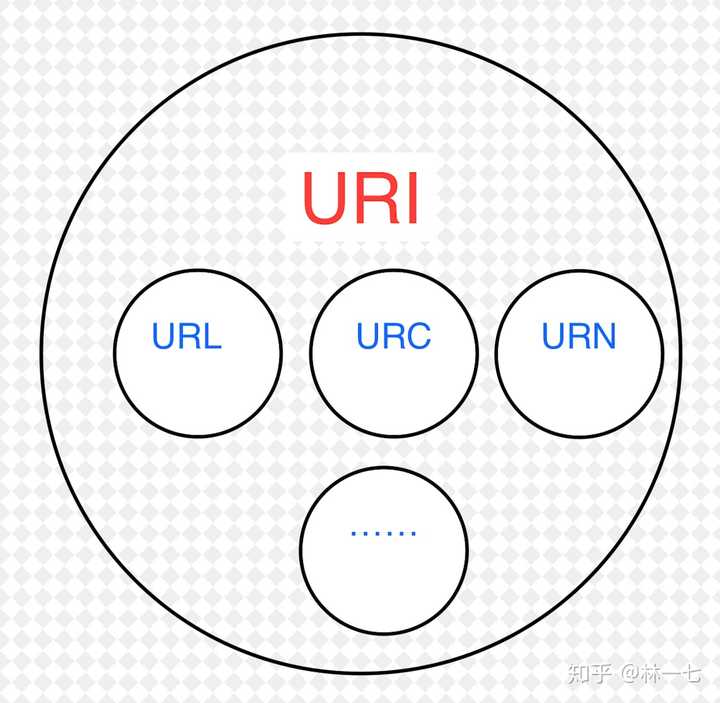 编辑于 2019-12-11
编辑于 2019-12-11